

 Search News You Can Use
Search News You Can Use
Episode 100 - September 11, 2019
 Search News You Can Use
Search News You Can UseThis episode is a massive one for all of our readers in celebration of our 100th episode. All subscribers are given full access to amazing content including Marie's analysis of Google's new link attributes, changes to the Quality Raters Guidelines, 15 of MHC's favourite newsletter tips from the past, and so much more! This episode is being live recorded as a webinar (join us below).
Note: Much of the content below is normally provided only to paid subscribers
Live 100th Episode Podcast
In this episode:
- Search News You Can Use Episode 100 - September 11, 2019
- Live 100th Episode Podcast
- Algorithm Updates
- Possible update September 4, 2019
- MHC Announcements
- Celebrating 100 Episodes of SNYCU
- MHC received a facelift
- Can you beat MHC’s score?
- Google adds two new link attributes -- “sponsored” and “ugc” -- that join “nofollow”
- Google has updated the Quality Raters Guidelines! Here is what you need to know
- Article on scientific consensus and alternative health sites
- MHC’s Top SEO Tips & Newsletter Highlights
- John Mueller’s tips on ensuring structured data shows in the SERPs
- Bill Slawski discusses the Knowledge Graph’s autonomous updates
- Our very first SEO challenge: earn more featured snippets
- The first of our page speed series
- Pedro Dias defines quality
- Luke Carthy on how to test your structured data
- Can unnatural links hurt a site algorithmically?
- Google retires rel=prev / rel=next
- Kevin Indig explains semantic content and entities
- Read the Quality Raters Guidelines
- Bill Slawski’s analysis of the PageRank patent getting updated to include trust
- John Mueller’s advice on pointing unnatural links to a burner site and redirecting to your own
- Awesomeness is a ranking factor
- Flash Content may prevent you from transitioning to mobile-first indexing
- The North Face takes on Wikipedia
- Google Announcements
- We say Goodbye to Old Google Search Console
- Google partners with the Mayo Clinic on health innovation
- Rich Results Test tool is out (beta version)
- Structured data markup for movie carousels
- Google SERP Changes
- A change to recipe SERPs on desktop was spotted
- You can now find movies and tv shows in the SERPs
- Bing is testing scrollable tab snippets
- SEO Tips
- Did you know that too many DMCA takedown requests can impact your ability to rank well?
- Does rel=canonical need to strictly be in the ?
- GSC & URL inspection signal issues but the Test Live URL says everything is okay – John Mueller tells us which to rely on
- What’s the deal with the rel=“noopener” attribute? Does it pass link juice?
- #AskAWebmaster Video – Canonical URLs: How Does Google Pick the One?
- The impact of adding schema to old content
- Discover your Reddit and Hacker News mentions with ease
- H-tags won’t make or break your rankings, but they shouldn’t be overlooked!
- Greg Gifford’s ‘most important SEO tip’
- Looking to improve your technical SEO skills? Check out this thread of recommendations on where to start!
- Other Interesting News
- Google touches on how they handle content accuracy
- Google Ads have banned unproven and experimental medical techniques
- Google appears to have different views on untrusted medical content when it comes to organic vs. paid results
- Update your WordPress plugins and core ASAP!
- Local SEO - Google Announcements
- Addition to practitioner section in GMB Guidelines
- Local SEO - Google SERP Changes
- Competitors local listings above the branded local knowledge panel
- Google testing GMB slider in the Discover feed
- Local SEO - Other Interesting News
- GMB bug alert
- Google My Business edits do what!?
- SEO Tools
- Puppeteer Recorder
- Recommended Reading
- Recommended Reading (Local SEO)
- Jobs
Algorithm Updates
Possible update September 4, 2019
There were a number of sites that we monitor that saw increases or decreases in Google organic traffic on this date. At this point, we are not seeing any obvious patterns to explain why. Barry Schwartz also wrote about a possible update on this day.
This update may be related to the link related update we suspect happened last week. If this change becomes more significant, we will do more investigation and follow up in a future episode. We will also be talking about the link related update in our live podcast episode that accompanies this newsletter.
MHC Announcements
Celebrating 100 Episodes of SNYCU
Did you enter the newsletter giveaway contest? We’re announcing the winner during our live webinar at 1pm! For the 100th newsletter, the MHC team has selected some of their favourite SEO tips and/or highlights from past editions. You can find all 15 of them below!
As a thank you to our subscribers, this episode is available to paid and free subscribers, so everyone can access this newsletter in full!
MHC received a facelift
We thought it was time to make some changes to the MHC brand and reflect how we identify as a team. We are not changing our values or our ideology but we are excited to say we have a new logo! Look out for our changes across social. We also have a website revamp to follow in the next few months, so we’ll keep you posted when that happens!
Can you beat MHC’s score?
As a special treat, one of our team members, Andrew Nguyen, has created a game to celebrate our 100th episode! Head over to our Wix site and give it a try! Tweet at @WixSEOLovers with your highscore to see if you can beat ours.
Google adds two new link attributes -- “sponsored” and “ugc” -- that join “nofollow”
This is HUGE news. In 2005, Google announced that site owners could use <rel=”nofollow”> in their HTML for links that you don’t want counted in the link graph. For example, most sites with comment sections will automatically nofollow all outbound links from the comments in an effort to stop people spamming just to get a link. Similarly, if someone purchased a link on your site, it would be appropriate to add rel=nofollow so that that link would not pass PageRank.
Now, Google is asking us to make some additional changes. At the time of writing this, though, it is unclear why a site owner would want to implement these changes.
There are two new additions we can add to our HTML in regards to links now:
rel=”sponsored”: For advertisements or paid placements
rel=”ugc”: For user generated content
Today, we’ve announced two new link attributes - “sponsored” and “ugc” - that join “nofollow” as ways to identify the nature of links. All will now work as hints about which links Google Search should consider or exclude for ranking purposes. More details:https://t.co/V6X2xjEC5L
— Google Search Central (@googlesearchc) September 10, 2019
We do not know why Google is making these changes, but we have some thoughts.
We think it is possible that Google may want to start using some nofollowed links in their algorithms. Right now, if a link is nofollowed, it means that Google does not use any of the signals associated with that link. This means that if the Wall Street Journal was to write a story about you and link to you with a nofollowed link, no PageRank would pass through that link.
The Quality Raters’ Guidelines talk extensively about how important it is to have recommendations from other people or websites seen as authorities in your topics. While we do think that Google can use nofollowed mentions in news sites for entity recognition, with the current system, those mentions would not pass PageRank if nofollowed. We feel it is possible that Google may start to count some nofollowed links from authoritative sites even if they are nofollowed. However, if those sites have links marked as rel=sponsored they are likely to be ignored.
We’re uncertain about the rel=ugc delegation. It may be possible that Google will still ignore all UGC links. But, we think it is also possible that Google may implement algorithms to assess some links in the comment section of certain sites. For example, if a health article has loads of comments where people say, “Wait, but Mayo Clinic says differently….<link>...”, perhaps Google will want to follow that link. (This theory goes along with our thoughts on how Google could be devaluing sites that have content that contradicts scientific consensus. )
What we don’t understand is what kind of incentive there is to site owners to make these changes. Google has told us that it is perfectly fine to leave your nofollowed links as they are and just ignore the rel=ugc and rel=sponsored options.
https://twitter.com/dannysullivan/status/1171488611918696449?s=20
Hopefully Google gives us more information on this. For some, making changes will not be a big deal. But for others, they may need to manually add a number of HTML changes. Also, new WordPress plugins will need to be developed and many CMS’s will need to be changed as well in order for site owners to be able to comply.
Added just before publishing...here are a few more questions about this change that have been answered for us:
The new rel=sponsored and rel=ugc tags will not be honoured in your robots tags in the head of your document
Yeah, this came up a couple times internally and no, we don't plan to support the new rels in robots meta
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) September 11, 2019
You cannot use an X-robots tag for these link attributes
No
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) September 11, 2019
In most cases, nothing has changed. We think this means that Google will start counting some nofollowed links towards PageRank, but only if they are clearly not sponsored, not UGC and are true recommendations from authoritative sites.
Various SEOs: how does changing nofollow to a hint affect A, B, C?
Us at Google: as we said in our post, it won't change the nature of how we treat links in most cases.
Various SEOs: but D, E, F?
Us: Won't change the nature of....
Various SEOs: but GHIJKLMNOPQRSTUVWXYZ.... pic.twitter.com/RgMlxjKiOS
— Danny Sullivan (@dannysullivan) September 11, 2019
It seems that most site owners will be adding the new rel=”sponsored” or rel=”ugc” on new links going forward, but not updating old ones
SEOs: Will you be using rel="ugc" and rel="sponsored" instead of / in addition to rel="nofollow"?
(Please retweet)
— Kyle Byers (@Kyle_Byers) September 11, 2019
We’ll end this section with a cryptic quote from Gary Illyes.
I know ☺️, i just wanted to point out that thinking about the new rels is not really the important announcement 🙂
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) September 11, 2019
What is he saying here? We think that the important part of this whole announcement is not that we should start using rel=”sponsored” and rel=”ugc” but rather that Google is treating rel=”nofollow” as a hint now, and not a directive. This is unlikely to mean that a site that spent years spamming blog comments is suddenly going to have some of those links start to count. Rather, we feel that Google will start counting some links that are marked as nofollowed but truly are recommendations from authoritative sites.
Google has updated the Quality Raters Guidelines! Here is what you need to know
When Google updates the QRG, we pay close attention. At MHC, we firmly believe that if something is in the QRG, there is a very good chance that it is either being measured algorithmically by Google, or that Google wants to measure it algorithmically in the future. The changes in each new edition of the QRG can often give us clues to what has changed with core algorithm updates.
There were quite a few changes in the most recent edition of the QRG, released on September 5, 2019. Here are our thoughts on what has changed and why these changes could be quite significant for some sites.
Huge emphasis on original content - important for news sites and informational sites
In several places, the QRG have changed to emphasize the importance of having original content. If you recall, one of Amit Singhal’s 23 questions to ask about your site’s quality, is the following:
“Does the article provide original content or information, original reporting, original research, or original analysis?”
The following similar quotes were all added to the QRG. First, we are told that for content to be considered “very high quality”, it should contain information that would not otherwise have been known had the article not revealed it. It also recommends that journalists list their primary sources and other original reporting referenced:

This is important! We review so many sites that take the news and simply rehash it. If your website regularly publishes news, unless you are seen as a leading authority in your industry, you absolutely must add additional angles to each story if you want Google to rank this content. We feel that in the future, if a site contains a large amount of content that is essentially rehashed and doesn’t add value on its own, it will be at risk for seeing ranking drops.
If you feel that your site may be guilty of producing content that is not likely to be considered original reporting, we would recommend a thorough content audit. Ask yourself the following of each post:
- If a reader read your post on this subject and also the originator’s post (or posts on an authoritative news site, etc.), would they find significant value in reading your article?
If the answer is no, then you have a few choices:
- Add more information that is unique, not just in words, but in how helpful it is to users.
- Noindex this post. This will make it so that it is available on your website, but is not in Google’s index. Keep in mind, however, that links to a noindexed article may eventually be ineffective.
We would recommend for all news sites moving forward that you work hard to make it so that readers truly find your content the most helpful of its kind.
Google may consider use of original images and video a sign of higher quality
This part of the “Very High Quality Main Content” section was interesting.

Currently, we do not feel that Google is applying E-A-T filters to image search. A search for “natural cures for cancer” will organically surface trusted medical sites such as the Mayo Clinic. But in image search, many of the sites that still rank well are ones that have been suppressed organically:

Note, we have just published an article on our thoughts on what Google is doing with alternative health sites.
Going back to the QRG changes, we think that Google will start applying E-A-T filters to image search as well. This means that in order to rank well for image search, for YMYL queries, you will need to have all of the elements of trust that we have been writing about for some time now.
We also think that Google will get better at recognizing when images are original and helpful. Does this mean that sites with stock photography will get devalued? Likely not. But, if you want to rank in image search, we anticipate there will be changes in the future so that original images rank higher, and also so that for YMYL queries, only images from trustworthy sites will rank well.
Clarification on what YMYL is
Google made a few clarifications in this area. They describe YMYL by saying, “Some types of pages or topics could potentially impact a person’s future happiness, health, financial stability or safety. We call such pages, ‘Your Money or Your Life’ pages, or YMYL.”
The words, “or topics” has been added to the above paragraph. This could possibly represent a difference in how Google determines if perhaps certain parts of pages are YMYL. This change is also reflected in other places in the QRG. In one place, they changed, “For news and articles and information on YMYL topics…” to “For YMYL topics…”.
We feel that Google will get better at determining which parts of content are to be considered YMYL.
They also made some changes in how they describe YMYL pages. Here is what this section used to say:

And here is what it says now:

Important info for shopping/transactional websites
We have known for a while now that Google likes to see evidence of good reviews for a business or its products. The highlighted section below was added to the QRG. We found it interesting that they now say, “experts could include people who have used the store’s website to make purchases.” We feel that it is possible that Google will put more emphasis on reviews that come from actual users of your products.
We have recommended for a while now that your website contains testimonials from happy customers. This may be even more important now.
Article on scientific consensus and alternative health sites
In case you missed it on Twitter yesterday, Marie published an article discussing whether Google suppresses alternative health sites that contradict scientific consensus. It’s definitely important to consider that there is a difference between accuracy and consensus when reading the article. Let us know what you think!
MHC’s Top SEO Tips & Newsletter Highlights
John Mueller’s tips on ensuring structured data shows in the SERPs
Featured in: Episode 43
Selected by: Callum Scott
In a July 2018 Help Hangout, John Mueller gave webmasters three great tips for ensuring structured data shows up in the SERPs:
- The markup needs to be technically correct.
- The markup needs to be logically correct. For example, if you have a post about bicycles that uses recipe markup, that markup is likely not going to result in review stars, etc. in the SERPS.
- The website needs to be considered high quality.
> Why Callum chose it:
“In particular I like that John emphasizes that to get a rich result, it is not simply enough (nor a good idea) to pack your page with every kind of schema markup you can think of -- it needs to make sense, and even then if your site is low quality, Google is under no obligation to display it.
For example, there is good reason to believe that for recipe pages, you should use recipe markup, not HowTo. Also, Google has told us that they will only display one kind of rich result for each result. So why add more than is really needed? Work on your content and site quality, and choose what makes sense for users and your site!”
Bill Slawski discusses the Knowledge Graph’s autonomous updates
Featured in: Episode 56
Selected by: Callum Scott
Still one of my favourite articles from Bill Slawski on how the Knowledge Graph autonomously updates by asking questions of identified elements (nodes) through the use of disambiguous query terms and past user searches.
> Why Callum chose it:
“This is one of the first really meaty articles that I read on the knowledge graph after starting at MHC, and it is for sure a bit of a cornerstone for my fascination with knowledge graphs and in particular how exponentially important it is developing as an influencing factor in organic search.”
Our very first SEO challenge: earn more featured snippets
Featured in: Episode 1
Selected by: Marie Haynes
Initially when I created the newsletter, my hope was to do monthly challenges to help everyone improve their SEO. Our first challenge was one in which we encouraged people to experiment to win more featured snippets using the information in this thorough document on how to win featured snippets.
> Why Marie chose it:
"My goal in creating this newsletter was to find as many ways as possible for people to learn about SEO, implement changes, and see improvements in rankings and traffic. Featured snippets are incredibly rewarding to play with and winning them is addictive!"
The first of our page speed series
Featured in: Episode 11
Selected by: Marie Haynes
In June of 2017, we started a series containing practical and easy to understand tips to help site owners improve their page speed. The page speed series starts here (it’s only available to paid users though). The first tip is about browser caching. Our goal was to make it very simple to understand.
In the episodes that follow we talk about other WordPress plugins you can use to help improve speed if you have a WP site and many other easy to implement tips as well. If you follow along, you’ll see that we improved our own site’s speed scores dramatically after making changes.
> Why Marie chose it:
"Prior to writing this early newsletter item, I found that every post I read on how to improve PageSpeed was incredibly technical. The goal in this series was to give the average site owner very easy to implement tips to help improve Page Speed."
Pedro Dias defines quality
Featured in: Episode 85
Selected by: Matt Baker
Everyone strives to have a high quality website, but what if what your targeting falls short of the very definition? Luckily, Pedro Dias breaks down the areas most SEOs target and what they often miss.
https://twitter.com/pedrodias/status/1131558598423842816
> Why Matt chose it:
“At MHC we focus much of our time on our Site Quality Assessments. As Google’s algorithm gets more sophisticated day-by-day, it’s important to understand that your impression of a good site may not necessarily align with that of your users! This visual from Pedro is an excellent reminder of what composes quality, and more importantly, what areas of quality your site may be lacking! That means fulfilling an answer (being useful), outlining the facts, figures, and trusted opinions (being credible), and demonstrating value above all else out there (desirable). As Barry Schwartz has said, make a website that Google is embarrassed not to rank!”
Luke Carthy on how to test your structured data
Featured in: Episode 82
Selected by: Matt Baker
You’ve worked hard to implement your structured data and now it’s time to test...did you know there’s a more effective way to do it? Hats off to Luke here for this SEO pro tip which suggests that you should paste in the HTML from Google Search Console’s live inspection to the structured data testing tool (instead of a URL) as there may be discrepancies between mobile and desktop!
SEO Pro Tip:
When using G's structured data testing tool, paste in the HTML from search console live inspection instead of a URL.Google's SD test tool uses a desktop bot - google itself uses mobile fetched SD
TL;DR If mob/desktop SD is different, the testing tool won't see it.
— Luke Carthy 🔎 (@MrLukeCarthy) May 2, 2019
> Why Matt chose it:
“There’s a good chance that you’ve already been moved to mobile-first indexing, and if that’s the case, you’d sure want to know that Googlebot is properly indexing your mobile version of your page! It would be a shame if you worked incredibly hard to implement structured data, only for Google to not recognize it when it matters most.”
Can unnatural links hurt a site algorithmically?
Featured in: Episode 67
Selected by: Alec Brownscombe
One of the most fascinating tidbits in our newsletter so far was the result of some boots-on-the-ground reporting from Marie, who went to New York for a webmaster hangout session and asked John Mueller if it’s possible for a site to suffer from some kind of algorithmic suppression due to unnatural links even if there is no manual action issued for the domain.
> Why Alec chose it:
“John’s answer that Google may not trust a site’s link profile fully if there are quite a few unnatural links present in their backlink profile was definitely a revelation. While we had heard of this possibility prior to Marie asking John the question, to have it confirmed by a Google employee on the record was a bit of a bombshell. Prior conventional wisdom was that Google was ignoring these types of links anyway post-Penguin 4.0; they likely weren’t either helping or hurting, so it wasn’t worth auditing and disavowing links unless there was a manual action penalty handed down or a site was at serious risk of one in the future. Now we have a more nuanced view on when it might make sense to go ahead with a link audit and disavow for a website.
If you’re guilty of unnatural link building and haven’t been issued a manual action, it may still be worth cleaning these up!”
Google retires rel=prev / rel=next
Featured in: Episode 76
Selected by: Alec Brownscombe
This was a “whaaaaat?” moment for us here at MHC. Google’s documentation and webmaster hangouts in the past talked often about rel=prev and rel=next like it was standard best practice for handling a pagination series. Now we find out it wasn’t in use and hadn’t been for years!?
> Why Alec chose it:
“We still aren’t 100% sure on pagination best practices and we are eagerly awaiting updated documentation from Google on this. So far, Google’s statement has been to treat them like any other page and ensure they offer standalone value. It’s especially complicated knowing Google has also said that it will no-follow links on no-indexed pages over time. These paginated pages can be important access points in order to ensure deeper-level content is still crawled, remains in the index, and has link equity flowing to it! We now evaluate on a case-by-case basis whether or not these types of pages should be indexed and how a site should handle its pagination system.
Keep in mind John Mueller has said that while pagination folders -- domain.com/blog/page/1/ -- are fine, parameters -- domain.com/blog?page=2 -- are easiest for Google to understand when crawling.”
Kevin Indig explains semantic content and entities
Featured in: Episode 78
Selected by: Dylan Adamek
Kevin Indig, and his work on Semantic Content and Entities, has been instrumental in shaping the way we think about these algorithms and how they might be valuing content on such a massive scale. Entities simply put, are nouns (events, ideas, concepts, people, places, dates etc). Diving a little deeper Kevin, describes entities as “semantic, interconnected objects that help machines to understand explicit and implicit language.” Think natural language processing, think knowledge graphs. In addition to Kevin’s articles, he also has a number of great talks online, including this one from Optimisey.
> Why Dylan chose it:
“Our team at MHC is constantly having discussions attempting to get to the core of how Google’s algorithms work and how we can use that information to help clients grow their footprint in the SERPs. These entity concepts that Kevin explains so well, directly benefit how our team goes about conducting site audits and diagnose major quality issues.”
Read the Quality Raters Guidelines
Featured in: Too many episodes to count!
Selected by: Dylan Adamek
If you’re an SEO and you haven’t read the Google’s Quality Raters Guidelines, what are you waiting for?! Every time our team revisits these guidelines we learn something new about E-A-T or site quality in general. These topics aren’t just broad descriptions of what makes Experienced, Authoritative and Trustworthy site, there are explicit examples of what Google would like to show in the SERPs. So many great takeaways buried in there!
> Why Dylan chose it:
“When my colleagues and I started working for MHC in late August 2017, Marie would continuously talk about Google’s Quality Raters Guidelines. At the time, this document didn’t get much mention in the SEO industry and even more rarely “E-A-T” would be mentioned. Marie had a feeling that these quality guidelines where in some way playing an important role to that changes in rankings we saw for many of our clients. Fast forward to today and these topics from the QRG’s on site quality are commonplace. We’ve been following these topics from the very beginning and the QRG’s are likely the subject we’ve discussed most in our newsletter but there’s so much in this 160+ page document.”
Bill Slawski’s analysis of the PageRank patent getting updated to include trust
Featured in: Episode 30
Selected by: Cassie Downton
I’ve also picked a post from Bill Slawski as one of my favourite tips, but this one goes way back to Episode 30, which we published in April 2018:
Google has updated PageRank by adding Trust to the link graph. https://t.co/cKtL2w8ypf https://t.co/yldLzYnu8k
— Bill Slawski ⚓ 🇺🇦 (@bill_slawski) April 24, 2018
The gist of the article is that the original patent for PageRank was going to expire, so Google updated it. As Bill noticed, though, the update included information on how Google could build trust into their link graph as a way to combat the spam and manipulation. According to the update, Google would select a number of diverse trusted pages (called “seed pages”) and use the outbound links from these seed pages as a way to produce a ranking for pages in response to a given query. This is likely based on the premise that great pages tend to link to other great pages. If the shortest possible distance between two seed pages could be calculated, then the distance between a seed page and any given page could also be measured. If Google could determine which seed page is closest to a given page, then the algorithm could compare that distance to the known shortest distance between two seed pages and use that to produce a ranking.
> Why Cassie chose it:
“Not only was it a super interesting article, but it also sparked a lot of discussion and debate about the power of spam and which types of link manipulation may be less effective now, such as link farms and high volume link building. So does this mean that not all links are equal? Quality over quantity? We already knew from Google that Penguin can now ignore certain kinds of low quality links, so perhaps this is the other side of that coin: links from whatever these trusted seed sites may be have become very valuable, and links from sites which are algorithmically measured to be very far away from those seed sites are not valuable at all. So not only do websites themselves need to be aware of their E-A-T, it may also be applicable to their link profile, too, which is something I find pretty interesting!”
John Mueller’s advice on pointing unnatural links to a burner site and redirecting to your own
Featured in: Episode 73
Selected by: Cassie Downton
This is a more direct tip than my first one. It comes from John Mueller answering a question on the r/SEO subreddit about the effectiveness of pointing blackhat links at a secondary domain you’ve created just for this purpose, and then using a 301 redirect on those links to point them all to your actual domain -- essentially, creating spammy links that go through a detour before ending up at your main site in order to get the benefit of having links pointing at you, but making it less obvious that you built those links yourself.
Googlebot will follow up to five 301 redirects before it stops following that chain, but the thing about 301s is that by using it, you’re effectively telling Google that the final page is the canonical page, since that’s where you’re indicating that want users to end up at. And since the canonical is the one that Google uses to evaluate quality, it doesn’t really matter which site a redirect skips through along its way to the final page because that last page is the one that counts the most. To quote John directly:
“The 301 basically makes the main site canonical, meaning the links go directly there -- you might as well skip the detour, it's just as obvious to the algorithms & spam team”
> Why Cassie chose it:
“If you’re thinking to yourself that you’ve seen other sites doing this and they’re ranking well: trust us, it’s not worth it. I picked this tip because we see people ask variations of this fairly often: what’s the harm in redirecting unnatural links to your main site if you can just remove those redirects if you see drops? It’s because it’s generally really hard to know whether drops are due strictly from those spammy redirects, from other kinds of manipulative link building you’ve done, or even from general site quality issues that affect you as a whole. You could try removing the redirects to see what happens, but you may find that Google’s various algorithms don’t reassess your site in terms of quality for a few more months and by that time, so much else will likely have changed both with your site and within your competitive landscape that it would be very hard to detect whether particular links are helping or hurting your rankings. So just don’t do it… or if you do, make sure you call us when you inevitably get hit and need your backlink profile cleaned up.”
Awesomeness is a ranking factor
Featured in: Episode 21
Selected by: Summar Bourada
Google has over 200 ways to determine ranking, some known, some not. When Google, or one of their employees informs us of these, it’s important to not take it lightly. Here’s one that is just as significant then as it is now:
Awesomeness.
— John 🧀 ... 🧀 (@JohnMu) November 30, 2017
> Why Summar chose it:
“As the only non-SEO on the team, I didn’t want to pick anything technical so I settled for one of my favourite John Mu Twitter responses. John likes to keep things entertaining -- which is one of the reasons we love him -- but I actually appreciate this answer.
When asked about ranking factors, John replied with “Awesomeness.” In all seriousness, this is actually quite useful. We need to focus on providing great content for users that is beneficial to their needs. Google is continuously improving how they analyze content and while the word awesome probably isn’t in the QRG, it definitely coincides with quality content!”
Flash Content may prevent you from transitioning to mobile-first indexing
Featured in: Episode 49
Selected by: Andrew Nguyen
The original article on Search Engine Journal is misleading. Here John Mueller clarifies that it’s not Java Script that prevents a site from being Mobile First Indexed but rather it’s the Flash Content that doesn’t work on Mobile.
https://twitter.com/JohnMu/status/1039109483400769536
> Why Andrew chose it:
“Alright I am a little biased when it came to choosing this tip. This was one of the first items I summarized for our weekly newsletter and I used to be a flash animator and game developer back when I was in highschool. The gist of the tip is that Flash Content does not work on mobile and thus prevents the site from being mobile-first indexed. So if you run any Flash content on your JS powered sites it may not be indexed properly if you’re on MFI.”
The North Face takes on Wikipedia
Featured in: Episode 86
Selected by: Andrew Nguyen
The North Face used Wikipedia images to promote their brand across 12 article images. This broke their Terms of Service and it’s definitely not something we at MHC recommend. At the same time they received a ton of links from authoritative news sites linking back to them due to the scandal.
> Why Andrew chose it:
“As a marketer I love big marketing stunts -- just like this big one that happened back in May 2019. All this to say, be bold when planning your marketing stunts. I’m pretty sure a philosopher once said “For it’s only the bold who receive links”. Do something out there, do something for your community, do something worth talking about. As John Mueller says, “Awesomeness” is the only confirmed ranking factor.”
Google Announcements
We say Goodbye to Old Google Search Console
This past Monday Google announced that old GSC is now part of the history of the web. From now on, webmasters trying to access the old homepage or dashboard will be redirected to the relevant Search Console pages. Though change is hard, it seems like some of the old tools can still be found as Legacy Google Search Console tools. Here’s more on the topic:
We’re saying goodbye to our beloved old Search Console 👋. Join us in celebrating this moment 🥳 by sharing your memories using #SCmemories - check out our tribute in the blog https://t.co/2UijlU3jLq pic.twitter.com/oD2Pf1D0qS
— Google Search Central (@googlesearchc) September 9, 2019
Worried about the old Google Search Console going away?
Fear not! It seems @googlewmc is rolling out links to legacy GSC tools on the left sidebar (might still be a test, though?) #googlesearchconsole #gsc pic.twitter.com/s1wKe7bziL
— Lily Ray 😏 (@lilyraynyc) September 9, 2019
https://twitter.com/JohnMu/status/1171082950286479360
For a list of Google tools and reports which aren't in the new GSC but can instead be found at specific URLs, Cyrus summarized the Legacy GSC tools:
Super-handy bookmark: 12 Google Tools + Reports not yet in the new Search Console, but can still be reached at specific URLs. Includes:
• Remove URLs
• Crawl Stats 💯
• robots.txt tester 🤖
• URL Parameters Tool
• International Targeting
...and morehttps://t.co/2kRUf0aRtX pic.twitter.com/h2HUOwqKCG— Cyrus SEO (@CyrusShepard) September 9, 2019
And in case you’re trying to find the Change of Address tool, well, it hasn’t been the easiest thing to find. Feel free to bookmark it! Thanks to John (x2) for bringing this to our attention.
John confirmed the tool still lives at https://t.co/yjfiDrWsph. Just really hard to find. Even in search. Position 5 with no title. @Marie_Haynes maybe podcast shoutout worthy? pic.twitter.com/ZnO28Q2GSD
— John Morabito (@JohnMorabitoSEO) September 10, 2019
Google partners with the Mayo Clinic on health innovation
This could be interesting news:
Proud @MayoClinic has selected Google as its strategic partner on health innovation. We’re honored that @GoogleCloud & our technologies can help play a role as Mayo continues to advance medical research, virtual care & disease treatment to save more lives.https://t.co/oEy9WbRQni
— Sundar Pichai (@sundarpichai) September 10, 2019
Google will benefit from the experience of the Mayo Clinic doctors. The Mayo Clinic will benefit from the use of Google’s cloud services and also AI.
What we don’t know is whether this partnership will affect the health SERPS. We think it is possible this could be connected to Google’s seeming mandate to only rank trustworthy health sites.
Rich Results Test tool is out (beta version)
One of the new GSC features is the Rich Results Testing tool that allows users to test their structured data.
Move over Structured Data Testing tool & say hello to the Rich Results Testing Tool- https://t.co/HkmCgHXaKT! I've been hesitant over some of the new GSC features, but have to admit I like this better than the old.
— Kristin Tahirovic (@knmille7) September 5, 2019
Please note that not all rich result types or error types are supported yet (currently there are just nine types supported). Google also says that the results are not guaranteed to be accurate, or to guarantee appearance in search results.
John said on Twitter that he suspects the Google team will likely want to focus on either the Structured Data Testing tool or the Rich Results Testing tool. In the meantime, both are available for webmasters to use.
Be sure to check out Search Console Help Centre for more on the Rich Results Tool.
Structured data markup for movie carousels
New structured data available for movie carousels has arrived. You can see it here. It includes the title, director and an image. We definitely recommend including this to your site if you have movies listed.
📽"You can't handle the markup!"🍿There's new structured data documentation for Movie carousels 🎬: https://t.co/JU6iGtPi5x
— Google Search Central (@googlesearchc) September 5, 2019
For those of you who have movie listings on your site, you should also know that Google has made some changes with respect to how users can browse movie via search. (See below)
Google SERP Changes
A change to recipe SERPs on desktop was spotted
Google is testing out showing three recipes on top, with everything else pushed below "Show more". Check it out:
This appears to be new on desktop (and I really like it).
First time Google has made a layout change I support in a long time. Shows 3 recipes at the top, pushes roundup lists below the 'show me more'. pic.twitter.com/jmJJNjago9
— Joe Youngblood (@YoungbloodJoe) September 3, 2019
You can now find movies and tv shows in the SERPs
Google has added a feature where you will be able to find movies and shows in the mobile SERPs. It will give you suggestions to cater choices to you and then provide suggestions. Should you be a host of movie and television content, this could very well impact your click-through rates!
Bing is testing scrollable tab snippets
We don’t cover Bing SERP changes all that often but this one was rather neat! It looks like Bing is testing a new layout within their Search results snippets that shows multiple tabs in a carousel that searchers can scroll through. Here’s a preview courtesy of a user on Twitter:

SEO Tips
Did you know that too many DMCA takedown requests can impact your ability to rank well?
https://twitter.com/dannysullivan/status/1170713562194440195?s=20
This started with Google’s Pirate Update several years ago.
Does rel=canonical need to strictly be in the <head>?
The rel=canonical should be in the <head>, and according to G, you’ll want to include it as early as possible. Adding the rel=canonical to your body will be disregarded, so make sure you include it only where it will be used!
This may help. https://t.co/bvMA31lrUe pic.twitter.com/laY0hOBnDK
— Marie Haynes (@Marie_Haynes) September 5, 2019
GSC & URL inspection signal issues but the Test Live URL says everything is okay – John Mueller tells us which to rely on
On one hand you’re seeing issues flagged, but on the other, things appear to be working just fine. Understandably, this can be very confusing for webmasters, so which is the most accurate? John says that if the live test isn’t showing any concerns, then rely on that information!
What’s the deal with the rel=“noopener” attribute? Does it pass link juice?
In regards to "PageRank and other signals", Googlebot only looks to see "nofollow" on links... any other rel-attribute doesn't matter when passing value through links. So if you're using something such as rel="noopener" as a way to sculpt PageRank, it's probably not doing a whole lot. Just stick to Google's guidelines on linking, and use the follow (or nofollow) directive on the links which truly provide value and that you endorse.
https://twitter.com/JohnMu/status/1169163626101579776
#AskAWebmaster Video – Canonical URLs: How Does Google Pick the One?
Another episode of #AskAWebmaster is out and it covers one of the more tricky subjects in SEO...canonicals! The video reveals the reasons why webmasters may select a canonical based off of Google’s preferred methods, but it may not be honoured. Keep in mind, Google wants to showcase the best, most representative pages in search. Here are some considerations when they choose:
- Which URL does the site prefer?
-
-
- Factoring in: rel=canonical, redirects, internal linking, sitemap file URLs, HTTPS URLs over HTTP, and cleaner URLs.
Pro tip: Consistency and accuracy in implementation is key!
- Factoring in: rel=canonical, redirects, internal linking, sitemap file URLs, HTTPS URLs over HTTP, and cleaner URLs.
-
- Which URL is most beneficial for the user?
Should a different canonical happen to be chosen from time-to-time, it’s not going to negatively affect the site. Check it out:
This week on #AskGoogleWebmasters, @JohnMu discusses how Google Search chooses a canonical URL from similar or duplicate pages.
Check it out → https://t.co/2tuSk12qJv pic.twitter.com/cq02J8XdIi
— Google Search Central (@googlesearchc) September 4, 2019
The impact of adding schema to old content
https://twitter.com/AlanBleiweiss/status/1169339135380705280
Seems to have been a successful test! Here's what schema was added:
https://twitter.com/AlanBleiweiss/status/1169392533207539714
Also, and updated comparison:
https://twitter.com/AlanBleiweiss/status/1169656897978290176
Discover your Reddit and Hacker News mentions with ease
Want to see the hacker news mentions to your site? Sometimes in these instances, your content can be submitted without your knowledge, so it may be good to see what is happening. Follow the steps in Cyrus’ tweet to test it out.
Easily Discover All the Reddit and Hacker News Mentions To Your Website
Admit it, once you know this - you'll race to try it 🏃♀️
via @IrishWonder https://t.co/zPjVZdPtCn pic.twitter.com/kUdgA3tAuc
— Cyrus SEO (@CyrusShepard) September 9, 2019
H-tags won’t make or break your rankings, but they shouldn’t be overlooked!
In a recent thread on Reddit, John Mueller said that header tags (ie. h1’s, h2’s, h3’s, etc.) won’t make or break your rankings, but they’re important for users to understand your content and should be used naturally. He also says that strong content is relatively longer form and would ideally have structure (and h-tags) in place to not only communicate what the page is about, but also to highlight key sections of information for users should they look at the page at a glance.
Also this week, John said that h-tags should be used over font size. To ensure you’re communicating clearly with search engines, headings are far more useful!
Greg Gifford’s ‘most important SEO tip’
Content is the basis of SEO, and without it being truly exceptional, you’re not going to outrank the competition. If you want to effectively communicate with your audience, convert, or earn links, your content matters! So to stand out, you need to connect with human users, not just keywords. Which brings us to Greg’s tip: Just read your content out loud. Speak it! Make it conversational, and allow it to mimic a face-to-face interaction.
Looking to improve your technical SEO skills? Check out this thread of recommendations on where to start!
What would you put on a Technical SEO reading list for someone looking to level up?
— Mic King (@iPullRank) September 5, 2019
Other Interesting News
Google touches on how they handle content accuracy
Danny Sullivan says that Google's algorithms can't verify the accuracy of information, but they can use other signals about authority and relevancy to a topic that can (this apparently doesn't include popularity, though). More explanation:
https://twitter.com/dannysullivan/status/1171407900327235584
We have covered this more thoroughly in our recent article on what is happening with alternative health sites in the SERPS.
Google Ads have banned unproven and experimental medical techniques
This is an interesting update to the medical and health ad policy especially considering all that has happened with medical sites lately. This includes stem cell, cellular and gene therapies, or those with no scientific basis. Google stated that they can lead to dangerous repercussions and they do not want to be associated with that.
Google appears to have different views on untrusted medical content when it comes to organic vs. paid results
Google: To protect the public, we demote any health site giving untrusted medical advice. Our standards are VERY high.
Also Google: May we suggest some sponsored cancer pills? pic.twitter.com/owxZaMu7Yr
— Cyrus SEO (@CyrusShepard) September 5, 2019
Update your WordPress plugins and core ASAP!
There are reported hackers using outdated versions of plugins to access your site. If you have any of the following plugins, you’ll want to delete or update them right away.
Bold Page Builder, Blog Designer, Live Chat with Facebook Messenger, Yuzo Related Posts, Visual CSS Style Editor, WP Live Chat SupportForm Lightbox, Hybrid Composer and all former NicDark plugins (nd-booking, nd-travel, nd-learning, etc.)
URGENT: Update your WordPress plugins and core. Big hacker attack underway the past few weeks. https://t.co/5Kr9WhNz5L #wordpress #security
— Joe Youngblood (@YoungbloodJoe) September 4, 2019
Local SEO - Google Announcements
Addition to practitioner section in GMB Guidelines
Google has made an addition to the practitioner section of the Google My Business Guidelines clarifying who qualifies as a practitioner and can get a listing. Thanks for this good catch Joy!
Google just updated the Google My Business guidelines and has added a line under the section for practitioners: https://t.co/hNRAbfQYmm pic.twitter.com/vO30wwOzha
— Joy Hawkins (@JoyanneHawkins) September 7, 2019
Local SEO - Google SERP Changes
Competitors local listings above the branded local knowledge panel
Uh oh, this one will not sit well if it sticks! Mike Blumenthal spotted this ‘competitor explore feature’ test in the SERPs recently. It was spotted over a year ago as well so it’s not technically new, but with Google recently beginning to show competitor ads on local business profiles, if this competitor carousel sticks local businesses will be quite vocal!
For f@(k’s sake Google.
Does a local brand search really need to surface competitors “to explore” above the branded profile?
Ok. It’s a test. Of what? How loyal a searcher is?
Seems like one big psych test pic.twitter.com/JIu3SLdWBM
— Mike Blumenthal (@mblumenthal) August 28, 2019
Google testing GMB slider in the Discover feed
The Google Discover feed has started to surface restaurant recommendations in a slider, under the title "Inspiration for your next meal out". Because Discover tries to automatically show content that it thinks a user may be interested in, users have the option to select that they're not interested in restaurants showing up in their feed. We're not sure how much of an impact this may have, especially since it looks like the listing doesn't open in Google Maps when selected by a user. You can read a bit more about this or see an example below.
Google testing GMB slider in Google Discover feed. Option to turn off if not interested in Restaurants. @rustybrick @mblumenthal @sergey_alakov pic.twitter.com/1Gfi6b8frI
— Brad Brewer (@Brad_Brewer) September 6, 2019
Local SEO - Other Interesting News
GMB bug alert
[GMB Bug Alert] Listings not appearing in GMB after accepting manager invites. This also seems to be impacting newly created listings.https://t.co/xAzD4Dagjj
— Joy Hawkins (@JoyanneHawkins) September 11, 2019
Colan Nielson originally posted about this in the Local Search Forum and Joy confirms that she’s seen many threads about this issue in the GMB forum. SEOs are waiting on a confirmation from Google about this, but if you’d like to stay-up-date, check out Joy’s link above.
Google My Business edits do what!?
This doesn't sound right, but thankfully there are a lot of anxious SEOs right now waiting for GMB Support to clear this up!
A rep from @GoogleMyBiz phone support told one of our clients that every change you make in your GMB dashboard sets your Google listing back to the beginning/zero/the bottom and you have to work your way back up. Can someone from Google Support please set the record straight?
— Darren Shaw (@DarrenShaw_) September 4, 2019
At the time of publishing, there was no update on this, but Darren -- along with many others -- have pointed out that this cannot be true as phone support is rather inconsistent and they often provide incorrect information.
SEO Tools
Puppeteer Recorder
Here's a handy Chrome extension which records interactions within the Chrome browser and generates a Puppeteer script.
Puppeteer Recorder is game-changing for tests: https://t.co/kE8FjO7Vbn ~ This Chrome extension records interactions & *generates* replay scripts 🤯 pic.twitter.com/HX4W513AsE
— Addy Osmani (@addyosmani) September 10, 2019
If you write code and test in Chrome, this can be a helpful time-saver:
This is game changing for startups & small teams. They can easily maintain integration tests and screenshot diffing checks for their web apps.
— Jash Sayani (@JashSayani) September 10, 2019
Recommended Reading
A 5-Step Guide to Diagnosing Technical SEO Problems – Alexis Sanders
https://www.searchenginejournal.com/diagnosing-technical-seo-problems-guide/322973/
Sept 4, 2019
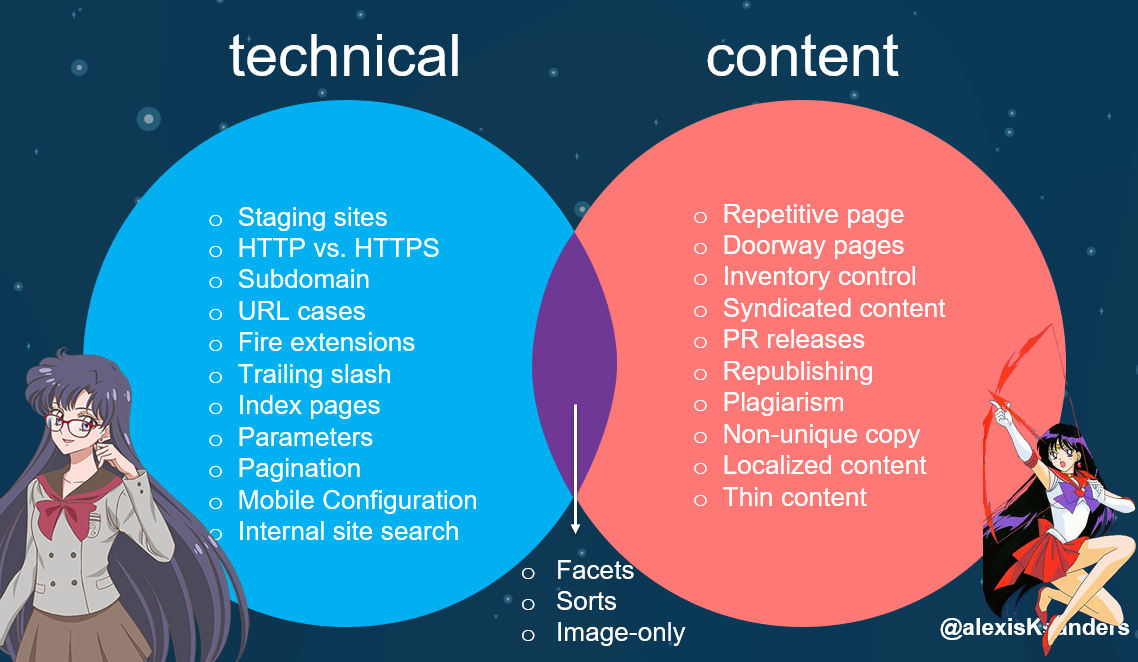
Alexis Sanders has put together a bookmark-worthy guide for diagnosing technical SEO problems with a series of worthwhile checklists (and handy graphics) to work through. In particular, her common roots of technical SEO problems and Venn diagram of technical and content issues are handy visuals to reference. If you’ve got technical SEO issues on your site or one of your client’s sites, before you panic or throw your hands up in frustration, Alexis has laid out a good number of “places to look” here so you can start digging into potential solutions.
{kind=link}
{kind=link}
SEMrush Q&A: Your Webinar SEO Questions – Melissa Fach
https://www.semrush.com/blog/semrush-q-a-webinar-seo-questions/
Sept 5, 2019
If you haven’t already heard, SEMrush is launching “SEMrush Q&A” where they take questions from all over the community and gather industry experts to answer them. This article includes questions from webinars and answers from Barry Schwartz, Marie Haynes, Joy Hawkins, and other awesome industry professionals.
We thought this was a great Q&A with Barry Schwartz:
Q: "What are some strategies that we can use to bring visitors from the snippet, and closer to our brand?"
Barry recommends using rich results schema and tailoring your title tags and meta descriptions to encourage clicks.
Here is another question we liked for those interested in local answered by Greg Gifford:
Q: What are your top tips for link building for small local businesses?"
Greg recommended going old school and doing things in your community, and we couldn’t agree more. “Sponsor local events, donate, find local bloggers..”
There are several more great questions and answers so we definitely recommend reading this article and following along with SEMrush Q&A for great, free advice.
“Impressions” is an Undervalued SEO KPI – Tom Capper
https://www.distilled.net/resources/impressions-is-an-undervalued-seo-kpi/
Sept 2, 2019
In this article by Tim Capper he goes over his thoughts on how he believes Impressions are an undervalued SEO KPI. Tim gives 5 reasons as to why he believes impressions are an important metric to keep an eye out on. Tim points out that Google is serving more clickless results and that much of the industry should play ball rather than complain. He notes that Google is able to interpret more search terms as informational and thus is able to serve the result right in the serps. Tim also points out that at times your can be ranking for keywords that you may not be targeting. Impressions can give you this information and you can be leveraging this information. Impressions should be used alongside other metrics including clicks to get a full picture of your marketing efforts.
The Invisible Attribution Model of Link Acquisition – AJ Kohn
http://www.blindfiveyearold.com/the-invisible-attribution-model-of-link-acquisition
Aug 30, 2019
In this post, AJ has done a fantastic job in explaining why both marketers and brands should worry less about “link building” and focus on “link acquisition.” Link acquisition, being much more than just receiving a link to your new piece of content. One of the mains points AJ makes is that signals that SEOs usually benchmark are asymmetrical and asynchronous - these links and mentions are coming from others recommending your content or products but it's very difficult to tell when and why exactly they entered the first stages of conversion. It takes time for someone to feel comfortable recommending something. So having a steady stream of content can do a lot for increasing exposure over time. He also notes that there is a huge benefit to “saturation” marketing and having eyeballs on your brand, backed up by an anecdote from his early marketing days and helping a client purchase ad space on a Nascar vehicle. This article articulates perfectly, why we shouldn’t be worried about getting one or two links from different sites but should be thinking about marketing in a broader much more long term sense.
Lessons I have learned from adding FAQ schema: A test of 1,000 keywords – Luca Tagliaferro
https://searchengineland.com/lessons-i-have-learned-from-adding-faq-schema-a-test-of-1000-keywords-321535
Sept 6, 2019
There as been a lot published in the last few months on both sides of the schema implementation debate. It seems like everyone is in favour of some structured data, however, it seems like no one can agree on whether certain kinds of schema hurt your website more than it helps. None has been more discussed than FAQ schema. We’ve tried to keep up with a lot of the articles, so this may seem like a familiar subject for our readers who have been with us since May, when Google announced FAQ rich results were coming to the SERPs. In this instance, Luca Tagliaferro released a brief case study on Search Engine Land where they added FAQ schema on their own website and looked at the impact it had for 1,000 of their keywords to see whether there was an increase in organic click-through-rate (CTR) or did the FAQs just give searchers the information they wanted directly from within the SERPs.
As he outlines, the benefit that you should see when you implement FAQ schema on your site is an increase in your organic CTR because the FAQ rich snippet is giving your site more real estate in the SERPs. Luca says they added FAQ schema to one landing page and doubled the organic CTR within 3 months for those 1,000 keywords being tracked. However, the article does mention that hyperlinks were included in at least some of the FAQ answers, which is one way that some SEOs have speculated could help compensate for lost CTR. Whether the benefit was from the FAQs themselves or the presence of the links within them is hard to know, but Luca does specify that there was no noticeable increase in clicks -- only an increase in CTR. Additionally, the keywords in question were transactional and not informational, meaning that -- as Luca says -- people still needed to go to the website to perform the conversion. So this case study may be further evidence that FAQ rich results are particularly great for websites selling a product or service.
Beyond conventional SEO: Unravelling the mystery of the organic product carousel – Brodie Clark
https://searchengineland.com/beyond-conventional-seo-unravelling-the-mystery-of-the-organic-product-carousel-321227
Sept 3, 2019
This is an important read for all eComm sites.
Do you remember earlier this year when Google started rolling out the “Popular Products” carousel in the US? Well that feature, which many originally believed was a mislabeled ad but is actually an organic result, is going to start being pushed out world wide soon. There was a lot of confusion around this new feature when it was first released. John Mueller alluded to it being part of the “product knowledge panel”, but not much more was known about it.
Australian based Brodie Clark has done some deeper digging into this new feature, assessing over 250 keywords across 20 different product segments. Here is what he found:
- The carousel is exceptionally prevalent on mobile. As Cindy Krum highlights, this is a great new way to rank products without actually ranking the product page - but it is being missed by a lot of SEOs as tools are not picking it up as an organic result (including GSC!).
- These carousels link first to a product knowledge panel before linking to your site. This is concerning since, often, anyone who sells that product is included in a price comparison grid for that products knowledge panel which could have a massive impact on conversion rates.
- “Popular Product” carousels appear the most often, operating with around 10 results, 5 of which are visible on desktop, 4 on mobile.
- Another carousel category is “Best Products” which take up quite a bit of real estate in the SERPs. These carousels are very details with an image, star review, and interestingly a mentioned in: section.
- The last type of carousel is “Similar Products” which appear when users are further down the conversion funnel i.e. have searched for a specific brand.
Brodie has also provided us with some really helpful tips for optimising for these new features. In particular he recommends ensuring you are using product mark-up schema, and also looking at submitting product feeds to Google via Merchant Centre. While Google Merchant Centre is often used for PPC campaigns, Brodie notes that you do not need to run an ad campaign to submit data within the MC which can be continually updated with latest product information.
The last thing to note is that aggregate review data is very prevalent in the carousels and the associated product knowledge panels. This includes data from wholesalers and competitors which, as Brodie explains, could end up having a negative affect on your conversions.
Recommended Reading (Local SEO)
How Does the Local Algorithm Work? - Whiteboard Friday – Joy Hawkins
https://moz.com/blog/how-does-the-local-algorithm-work
Sept 6, 2019
Local expert Joy Hawkins takes on her first ever Whiteboard Friday and it’s a good one! Talking about the local algo (ie. the three pack, also known as GMB listings & G Maps), Joy explains that it operates off of three main factors:
- Proximity (ie. where you’re located) - The local pack is different for users in different locations. As an SEO, she mentions tools that your use to check rankings in different locations, along with geo coordinate considerations that’ll allow you to hone in on clients within certain industries.
- Prominence (ie. how important your business is) - Links, store visits, reviews, and citations are considered here. It really helps to demonstrate to Google that you are a credible business that should not be overlooked!
- Relevance (ie. how relative are you to the given query) - Content, metas, citations, GMB categories, business name, and reviews/GMB Q&A have influence. Unless you can closely match the users query, it just wouldn’t make sense for Google to show your business.
This is a worthwhile watch packed with plenty of good knowledge. One tip that we quite enjoyed, was that in her testing of linking GMB listings to different pages of a site, her agency found that linking to the homepage has demonstrated the best results.
Jobs
Come work with us! We’re looking for a Sr. SEO Analyst to handcraft data-driven strategies. What’s in it for you? A fun, collaborative environment that encourages growth (and some pretty sweet benefits).
Apply👉 https://t.co/CevE6CbGB5 #SEOjobs #marketingjobs #digitalmarketing pic.twitter.com/nRkbpLvUkO
— Workshop Digital (@WorkshopMktg) September 6, 2019
We're hiring for six different Content Marketing Specialist positions in Austin and San Diego!
If you know anybody, send them our way. https://t.co/6Tva70VuTD pic.twitter.com/YblFMAFibm
— Ross Hudgens (@RossHudgens) September 6, 2019
Psst. Andrew here from MHC. You’ve made it to the bottom of our 100th Newsletter! Congratulations! As stated earlier we created a game to celebrate and I wanted to let you in on a little secret. If you enter the Konami Code in the menu screen you’ll get a nice surprise! (but be quick!)
![]()

