


A comprehensive guide to Google’s organic search ranking systems - Part 1
Introduction
Google’s system for ranking web pages has evolved dramatically over the years since it was first launched in September 1998.
This is part one of a series in which we will be providing a (nearly) complete guide to all the different known algorithms that make up Google’s search ranking system.
In part one we will be covering Googles Core Ranking System and all the algorithms we know it contains. This is the part of the ranking system that is updated with Google Core Updates.
Future parts of this series will cover algorithms and systems that are used in ranking such as the product reviews update, spam fighting systems, page experience algorithms, and many many more.
While SEOs and digital marketers will often refer to Google’s ranking system simply as “The Algorithm”, it is in fact made up of hundreds (if not thousands, or millions) of algorithms and systems designed to ensure that the results Google serves in the SERPs meet the high standards users have come to expect.
Google makes changes to the ranking systems multiple times a day. In 2021 they claimed that over 3,620 changes were made to their systems overall.
Some of these are minor but when a significant change is made to the ranking systems they will often announce this through one of their public channels.
These bigger changes are usually an update to an existing algorithm/system, or the launch of a new one.
Over the course of 2021, and in particular throughout the summer and fall months, there was a seemingly endless stream of updates being announced. However, what caught our eye was the number of different announcements for updates or launches of specifically named systems.
One of the most common misconceptions we hear from both clients and within the search community is about what parts of the search system do what. Unless you are (like us!) keeping on top of every single announcement and change made at Google, it is incredibly easy to get mixed up about what update or algorithm does what!
We hope that this breakdown will help you better understand how these systems work, interact, and may ultimately impact your SEO performance.
Why we are qualified to write this article
At MHC we diligently track and analyze all the known and suspected changes within the organic search ecosystem. We monitor the rankings and traffic for a large number of current and past client sites on a weekly basis to produce insights for our premium Search News You Can Use newsletter subscribers.
We also work directly with site owners that have been affected by updates/changes in search to provide them with a comprehensive understanding of the impact, and build them strategies for their organic SEO performance going forward. In doing so, we have analyzed thousands of data points surrounding the impact of when these systems are introduced and/or updated.
Notes on our process
The vast majority of this is based directly on statements and announcements made by Google spokespersons or within their official documentation. We have provided sources as much as possible, and noted where we are expressing opinions/making assumptions.
We also wanted to note that while there is a notable difference between a singular algorithm (such as PageRank) and larger systems (such as Google’s spam fighting systems), colloquially the terms are often used interchangeably by both SEOs and Googlers alike – which may occur from time to time in this article. Please don’t think less of us for that 😉
We have also for the most part focused on systems involved in the ranking portion of search and less on the systems that govern crawling and indexing. We will hopefully cover these at a later date!
Google’s Core Ranking System
When we refer to Google’s Core Ranking System, we are talking about the main engine that drives the production of individual search engines results pages (SERPs) when a searcher enters a query into Google, and hits enter.
Optimizing websites to be favored by this system is largely what we are trying to achieve as SEOs.
The system has evolved a lot over the years and the inner workings of how the system works remains largely a secret from everyone aside from Google engineers (and possibly even them – more on that later).
What we do know about the core system has come from the endless hypothesizing, testing, reverse engineering, research, and information sharing within the SEO community over the past 20+ years.
We have also been told by Google on occasion when an algorithm that was previously being applied separately at a different point in the ranking process has been integrated into the core ranking system such as when the Panda algorithm was in January 2016.
The following are all the known algorithms within the core ranking system.
The PageRank Algorithm
PageRank is probably the most well-known part of the search ecosystem and as far as we know, it is still one of the most important algorithms involved in producing search results.
The algorithm was designed by Google founders and engineers Larry Page and Sergey Brin in 1996 while at Stanford University. The name is a play on both the importance of web pages within search, as well as a play on one of its inventor’s namesakes.
How does PageRank work?
PageRank is a form of link/citation analysis that (in simple terms) assigns a value between 1 and 10 to web pages that are linked together.
The value of PageRank assigned to each page is determined recursively. Every link from one page to another passes on a certain amount of the linking pages’ PageRank, to the linked page – in turn, this makes up the value of the linked pages’ score.
The amount of PageRank a web page has is used by Google to assert the authority and relevancy of a page for certain queries in comparison to other sites in consideration for ranking.
PageRank includes a reasonable surfer model which asserts that the average user will eventually stop clicking on links, and thus a damping effect is applied to the passage of PageRank between pages after a certain point.
When was the PageRank released?
The algorithm was filed as US Patent number 6285999 in 1998 and it has been a significant component of the core ranking system ever since the launch of Google. This novel approach of using links to ascertain page authority is arguably what made Google’s search results superior to early competitors, and thus gain the market share that it retains today.
Can I optimize for PageRank?
The short answer is yes. Gaining certain links to your webpage from other high PageRank web pages will increase your PageRank score, which in turn can have an impact on your search performance. However, only certain links will help you in this area in 2022.
In the early days of search, SEOs discovered that attaining large numbers of links from low PageRank sites (often self-made, a practice known as “link-bombing”) could also inflate their score and result in better rankings.
Since then, Google has been in a game of cat and mouse with SEOs to tackle different types of manipulative “link spam”.
How much impact does PageRank have on ranking?
In 2016 the company confirmed that links and content quality were still the top two ranking factors. While Google has many ways of measuring the importance of links to a site, we assume that PageRank is still one of the main metrics they use.
How do I know how much PageRank my site or page has?
You can’t know for sure. Back in the early days of SEO Google provided an in browser toolbar that showed the PageRank of the URL that was open in the browser, but this was taken away in 2016.
Some third-party tools try to provide scores that might approximate PageRank, such as Ahrefs Domain Rating (DR) and Moz’s Domain Rating (DA). However, in our experience these are not great at estimating page authority/link quality.
It is important to note that since 2013, when Google launched the Hummingbird algorithm, which will be discussed shortly, they told us that while PageRank was still important, it was now just one of over 200 important ingredients in the search algorithm.
Penguin 4.0 (September 23rd, 2016)
Penguin 4.0 (September 23rd, 2016)
The Penguin algorithm was first launched in April 2012. The purpose of this algorithm was to tackle “spamdexing” or what would these days be commonly known as unnatural/toxic link building. One of the main targets was the practice of link-bombing mentioned above.
The original Penguin algorithm supposedly impacted 3-4% of all indexed websites. However, if you ask a lot of SEOs from that time, they will likely tell you a different story!
In all honesty, MHC would not likely be here today if it wasn’t for the Penguin algorithm – Marie’s career really took off through her uncanny ability to release sites from the grips of Penguin (which could devastate a sites ranking overnight) through her astonishingly in depth understanding of link quality.
Penguin has gone through seven different iterations over a four year period. For the first six of these, the algorithm would run with each update and any sites impacted would have to wait until the next update to see whether they had been “released”.
On September 23rd, 2016, Google announced that “Penguin 4.0” had been integrated into the core ranking system and would now be running in real time – so we know for sure that Penguin is a component of the core ranking system.
How does the Penguin Algorithm work?
When it initially launched, Penguin was a special algorithm that Google would run from time to time. From its launch in 2012 until Penguin 4.0 in 2016, we saw several “Penguin updates”. Each was designed to identify widespread attempts at PageRank manipulation through link building and demote for it. Early versions of this algorithmic filter were severely punitive for some sites.
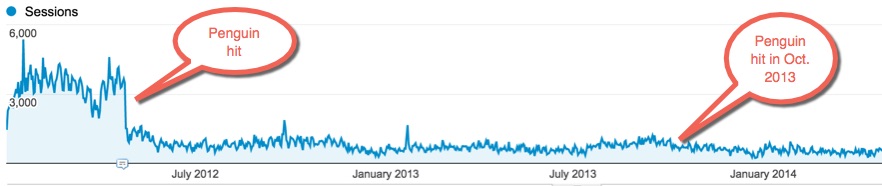
If a site was demoted because of Penguin, the only known way to recover was to either remove the unnatural links, or, after the disavow tool was introduced in late 2012, disavow them and then wait for Google to refresh the Penguin algorithm. If enough of the problem was cleaned up, then the suppression would lift off.

The timing of these periodic refreshes was very frustrating to SEOs and site owners who needed an update in order to see whether they would recover. Between 2014 and 2016, we went almost two years without seeing an update. Sites that were suppressed by Penguin had no way to recover.
In 2016, the Penguin algorithm changed dramatically so that it was, for the most part, no longer a penalizing algorithm.
How does Penguin 4.0 impact rankings in 2022?
In September of 2016, Google made dramatic changes to how Penguin works. The first change was to make it a part of the core algorithm. Instead of manually pushing out Penguin refreshes a few times a year, it was now running in real time. The second thing that changed, and still remains true today is that Penguin “devalues spam by adjusting ranking based on spam signals, rather than affecting ranking of the whole site”.
A few days following the announcement of Penguin 4.0, Gary Illyes shared that now that Google felt confident in their ability to simply ignore unnatural links, any sites previously suppressed by Penguin algorithmically would have those suppressions removed.
Today, Penguin is still a part of Google’s core ranking system. You can read more here about our current advice on evaluating your link quality and determining whether Google’s disavow tool could help you.
The Panda Algorithm
Like Penguin, Google’s Panda algorithm was originally a separate algorithm from the core ranking system that applied a filter to “low quality” or otherwise “thin” websites to prevent them from ranking as well.
There were 28 known updates to the Panda algorithm between its release in 2011 and 2015 when Panda 4.2 was “slowly released”.
On an undisclosed date in March 2012, the Panda algorithm was integrated into the core ranking system.
Panda is a very important algorithm in the Google ecosystem because it was arguably the first direct action that Google took towards rewarding sites that they could programmatically measure as being higher or lower quality. Page and site quality has become a more and more important aspect of how Google ranks content over the years.
As a known algorithm within the core ranking system that is focused on identifying the quality of a webpage, one could even argue that the seemingly significant changes to how Google assesses site/page quality in relation to queries with updates to the core ranking system (such as August 1st’s “Medic”) were in part due to updates to Panda.
When Panda first came out, most SEOs saw it as a filter to demote duplicate or thin content. It was much more than that though.
Panda was the impetus for Amit Signal to release his 23 Questions for recovery from Panda which remains one of the best guides for assessing site quality in the eyes of Google. These questions are the same ones that Google modified slightly in their blog post on what site owners should know about core updates. These questions include things like, “Does the content provide original information, reporting, research or analysis?” and “Does the content provide substantial value when compared to other pages in search results?”
How does the Panda Algorithm work?
As with Penguin, Panda was initially a filter that Google would apply from time to time. If you were negatively affected by a Panda update and did work to improve quality, the benefits of that work would not be seen until Google ran another update of Panda. Thankfully these were much more frequent than we saw with Penguin updates.

As of 2016, Panda also became a part of the core ranking system. It runs continuously and no longer needs manual refreshes.
How do you know if you were impacted by the Panda Algorithm?
Today, you likely will not know if you were impacted negatively by Panda as it runs in real time along with the core algorithm. If you saw a drop in organic traffic on a random date, it’s possible Panda affected you, but there is no way to say with any certainty.
How do you recover from the Panda Algorithm?
In the past, most SEOs would recommend that a Panda hit site focus on cleaning up thin content and removing content that has been copied from other sources on the web. This is still good advice today. But, Panda likely goes much deeper than this.
Given that Panda is a part of the core algorithm and deals with site quality, it’s impossible to separate out whether Panda has affected your site today.
If your site is not performing as well as expected and you feel that Google could be algorithmically determining that quality is not great, then we would recommend thoroughly reviewing Google’s questions in their blog post on core updates. (We have written much more here on core updates and how you can improve your site to have better quality in Google’s eyes.)
Quality Focused/E-A-T Algorithms
Expertise, Authority, and Trust, or “E-A-T”, is an acronym that originated in Google’s Search Quality Evaluator Guidelines. More recently, Google has referenced this acronym in a number of their documentation about core updates.
But what are the search quality evaluator guidelines?
The search quality evaluator guidelines is a document created by Google to teach human raters whom they hire to evaluate the quality of the sites and search results that are being produced by potential changes they want to make to search before they roll out any changes or updates.
The feedback provided by these raters has no direct impact on the current search results – but Google uses this feedback to assess the efficacy of updates or additions to search they want to make.
(By extrapolation, we can assume that producing search results that align with the criteria in the rater guidelines is Google’s goal for the updates to the systems they make.)
Prominent within the rater guidelines is the concept of E-A-T. E-A-T is a framework for what Google considers a high quality result, page, or website to be. Google’s E-A-T guidelines help us understand how to create high quality content.
This framework, according to the rater guidelines, should be added with more weight to queries and/or pages that fall into the realm of addressing issues related to Your Money or Your Life (YMYL). In Google’s guide to how they fight disinformation they say, “where our algorithms detect that a user’s query relates to a “YMYL” topic, we will give more weight in our ranking systems to factors like our understanding of the authoritativeness, expertise, or trustworthiness of the pages we present in response.”
You may find this Search Engine Land Article useful in which Marie discusses practical ways in which you can improve E-A-T for sites discussing YMYL topics.
E-A-T, and its impact on search ranking, has become a very hot topic within the SEO community. There is a lot of disagreement about how to interpret the importance of E-A-T for ranking, how to “optimize” for E-A-T, and whether E-A-T is even worth paying attention to.
In this author’s opinion, most of this disagreement comes down to semantics and misalignment about philosophies on how to approach the nebulous practice of SEO.
For anyone who has followed MHC for the past 4-5 years, you will likely know that we think that E-A-T is something webmasters and SEOs should pay attention to. But perhaps our reasoning has not been clear – as such it gets a special mention in this article.
Is E-A-T an algorithm? Is it part of the Core Ranking System?
E-A-T is not an algorithm. As explained above, it is a framework in the search quality evaluator guidelines for how Google defines quality pages and sites.
However, since around 2018 there have been numerous updates to the core ranking system that have resulted in changes in the search results that both MHCs data and analysis (as well as many others in the search community) show sites/pages that align with the indicia outlined in the E-A-T framework are rewarded over those who do not.
This shift in results, along with Google’s commitment to evaluate their systems against this E-A-T criteria, strongly suggests that there are algorithms within the core ranking system that are designed to identify sites/pages that match the E-A-T framework.
We just don’t know what they are! However, we do have some clues…
At PubCon Vegas in 2019, Google’s Gary Illyes was asked about how Google’s systems evaluate site quality and specifically E-A-T for YMYL queries.
He asserted that there is no singular E-A-T score or metric like there is with PageRank (which we don’t think anyone is arguing in 2022), but then explained that in the core ranking system there is a collection of “millions of baby algorithms” that work in unison to “spit out a ranking score”.
He then went on to say that these “Multiple algorithms conceptualize E-A-T”.
So what does that mean?
Well, at the very least it confirms that Google is actively developing ways to identify sites/content that have indicia of E-A-T (as outlined in the Quality Rater Guidelines) and use that information within its core ranking system to some extent.
This isn’t all that surprising. While identifying the quality of a website in line with this framework programmatically is indeed very challenging, as discussed above Google has been creating algorithms such as Panda to assess site quality since 2011.
Documents such as Amit Signal’s 23 questions on assessing what makes a high quality website line up with a lot of the elements associated with E-A-T as detailed in the search quality evaluator guidelines. Multiple patents filed by Google detail potential ways they could evaluate such things. As discussed below, they already are capable of identifying authoritative entities within their knowledge graph.
So while we ultimately don’t know how Google ‘s systems identify signals about a site/pages E-A-T, or specifically what those signals are, we do know that the core ranking system is being designed to take this framework into account for ranking.
If you are interested in hearing Marie speculate more on how Google could determine E-A-T you may find this podcast episode helpful.
When did E-A-T become part of Google’s Algorithm?
Since E-A-T is a framework and not a singular algorithm, we don’t know when Google started trying to use it as part of their ranking system. However we do know that the framework first appeared in the search quality evaluator guidelines in 2014.
The August 1st 2018, core algorithm update is often recognized as the first significant update where YMYL sites exhibiting indicia of E-A-T generally saw improvements.
At MHC we first noticed sites that had indicia “high E-A-T” as per the evaluator guidelines were making a lot of gains around February 7th 2017. There was another very notable change that occurred with the March 2018 core algorithm update for YMYL queries.
When are E-A-T algorithms updated?
While we don’t know exactly how Google measures E-A-T, we are pretty sure they do this as part of their core ranking system. Announced core algorithm updates occur around 3-4 times a year. At MHC we often see clients who have been working on aligning their sites to match the framework of E-A-T improve with core algorithm updates. It is possible that these systems also refresh sporadically or in real time throughout the year without Google making any announcements.
How can I optimize for E-A-T?
As Gary Illyes said at PubCon Vegas in 2019, E-A-T is best conceptualized as the result of millions of tiny algorithms that look to pick up signals that will help them identify high E-A-T sites, and use that information for ranking.
SEOs should first ensure a site is optimized for all the known ranking factors and is technically optimized for crawling and indexing – that is a given. But in highly competitive YMYL niches, it can often be the case that most of the sites you are competing against may be performing as well as you are in these areas.
To any extent, they are likely competing at a level where the signals become largely indistinguishable from each other in the eyes of a search engine trying to find the most relevant, expert, authoritative, and trustworthy piece of content to rank.
This is where Google’s “millions of tiny algorithms” come into play, and the SEO steps into a much more “grey area”.
To continue competing at this point, you need to create a site that is going to come out on top after those “million of tiny algorithms” work to assess your site quality within the framework of E-A-T.
No one can know or understand or guess what those millions of algorithms/ranking factors are.
As we will discuss later, it is possible (and in our opinion) likely that even Google engineers are not able to identify them!
To optimize for this darkest of dark blackboxes, we believe the best approach is to improve your site so that it aligns as closely as possible with what Google has openly outlined as what they are looking for in terms of site/page quality – which broadly speaking is E-A-T.
So read the quality rater guidelines and apply those insights to your site where applicable. Amit Signal’s 23 Questions are also great template to work with, as is the Stanford guide to website credibility that SEOs like Bill Slawski often recommend as an alternative.
In August of 2019, Google published a blog post about core updates. In the post they tell us to “get to know the quality rater guidelines and E-A-T.” (They also link to our guide on E-A-T as a reference.)
The following reference was added to the above document in March 2020:
 “Note (March 2020): Since we originally wrote this post, we have been occasionally asked if E-A-T is a ranking factor. Our automated systems use a mix of many different signals to rank great content. We’ve tried to make this mix align what human beings would agree is great content as they would assess it according to E-A-T criteria. Given this, assessing your own content in terms of E-A-T criteria may help align it conceptually with the different signals that our automated systems use to rank content.”
“Note (March 2020): Since we originally wrote this post, we have been occasionally asked if E-A-T is a ranking factor. Our automated systems use a mix of many different signals to rank great content. We’ve tried to make this mix align what human beings would agree is great content as they would assess it according to E-A-T criteria. Given this, assessing your own content in terms of E-A-T criteria may help align it conceptually with the different signals that our automated systems use to rank content.”
At MHC we have really found that (after all technical and known ranking factors are accounted for) this holds true. While it isn’t possible to measure these kinds of “metrics” directly (unlike say, page speed), by assessing sites through the lens of E-A-T, SEOs are able to find the gaps regarding what elements may be missing both on and off site.
This results in recommendations for improvements that are both good for users and in turn can give you an edge for rankings. Glenn Gabe refers to this as “The Kitchen Sink” method for traffic drop recovery, and we also highly advocate for it.
How to know if you have been impacted by an “E-A-T” quality update?
As far as we know, aside from Panda hits, most of the impact from updates that are focused on E-A-T/site quality have occurred with Core Algorithm Updates. So if you think you have been impacted by Google’s systems looking to assess E-A-T, you’ll want to look closely at the dates of core algorithm updates.
Up until around mid-2020, most impacts to a site’s ranking/traffic following a core algorithm update would be mostly noted on the day of the update.
For example, here is what a site we worked with saw following a drop on August 1st, 2018, with the Medic Update, followed by dramatic recovery 6 months later with the next Core Update.

This was the norm for algorithm impacts from the early days of Panda and Penguin until 2020/21. While we would occasionally have seen what we think are “tweaks” 1-2 weeks after an update, if a site has been “hit” by an update, you would expect to see a change on the day itself.
This has changed in the past few years with Google themselves acknowledging a longer rollout for updates:
https://twitter.com/dannysullivan/status/1384609506559086593
What this means is that impacts following an update can take a few weeks to be seen as the search ecosystem is continually affected. Moreover, this does make it harder to distinguish between the impact of different updates when they are stacked closely together.
How much impact has E-A-T had on organic search?
Since there wasn’t a specific “E-A-T” algorithm rolled out at any point, it is hard to tell how much impact Google’s choice to develop algorithms that identify and rank sites exhibiting indicia of E-A-T has had.
With that said, there have been numerous instances since 2018’s “Medic” where core updates that we assume had the goal of favoring sites with good E-A-T have had dramatic impacts on sites rankings and traffic.
Amongst the sites MHC monitors, we have seen the degree of these drops to (overall) become less severe with each update. Logically this makes sense, as each update in theory should be a refinement on the last – not a drastic reversal/U-turn in what Google wants to rank.
Of course, some sites will see either an unfair demotion or promotion in the SERPs when these algorithms are updated because Google is never going to get it right every time – understanding that risk is important for all SEOs and webmasters to know!
Hummingbird
The Hummingbird Algorithm was first announced as a part of Google’s search ranking ecosystem in September of 2013 after being in production (with very few in the SEO community noticing!) for a month.
The purpose of the algorithm is to put greater emphasis on the intent of a query by understanding the semantics of the search being made. This means looking past the meaning of the individual words in a query and looking more broadly at the semantics of the query. Danny Sullivan, who worked for Search Engine Land at the time, told us that with the release of Hummingbird, PageRank was now just one of 200 important factors in their search algorithm. Google made much more use of entities in search with the launch of Hummingbird.
This marked a big moment for Google using natural language processing for search. This has been advanced in subsequent years by other NLP technologies such as BERT and MUM.
The name derives from the ability of the algorithm to work with speed and accuracy, much like a real hummingbird. Interestingly, when it was announced, Hummingbird was billed as a complete overhaul to the core search system.
When was the Google Hummingbird algorithm released?
Hummingbird was released around August 2013. It was officially announced in September 2013 at Google’s 15th Birthday Event.
The Hummingbird algorithm was integrated into the core ranking system in 2016.

When is the Hummingbird algorithm updated?
The Hummingbird algorithm is part of Google’s core search system. It is updated with each Google core update.
How can I optimize for the Hummingbird algorithm?
You cannot directly optimize for the Hummingbird algorithm. The algorithm helps Google rely less on individual keywords and more on understanding searcher intent. Following the release of Hummingbird, SEOs are encouraged to focus on creating content that is written “naturally” and not filled with forced keywords.
With that said, MHC has recently been studying the increased emphasis that Google put on understanding entities and the relationships between them that began with Hummingbird. We believe that there are great advantages that can be gained by understanding your business’ entity profile across the web, and also by understanding how Google’s algorithms extract entity information from your pages.
Stay tuned to our newsletter and Marie’s podcast as we will share as we learn more in this area.
How to know if you have been impacted by Hummingbird?
Hummingbird was released in August 2013 and no one appeared to notice. To date, there have not been any major reports of significant impacts related to the update, which is not surprising given the nature of the algorithm and its purpose.
If you were affected by a core update, likely Hummingbird played a role here. But optimizing specifically for Hummingbird is not something that we recommend.
Venice Algorithm
The Venice Algorithm/Update is a part of the core ranking system that impacts local SEO. The algorithm works to improve the reliability and frequency with which Google knows to find and serve results from a searchers city.
Up until this point broad queries would seldom return localized results in the organic SERPs and serve Google Places (now Maps) results.
When was the Google Venice algorithm released?
Google’s Venice update was released in February 2012 in the USA. It rolled out across other markets in the following months.
When is the Venice algorithm updated?
Google’s Venice algorithm is part of the core ranking system. It updates with each Google core update.
Caffeine Update
Google’s Caffeine is not actually an algorithm but it is a very important part of the core ranking system and had a big impact on search when it was released on June 9th 2010.
The update meant a significant overhaul to Google’s back-end indexing system. The update allowed Google to index pages significantly faster and accounts for 50% fresher results.
The update did away with the older system by which Google would prioritize crawling and indexing based on perceived freshness in relation to the site category. So, news sites would be crawled frequently and new pages indexed, but other sites would wait weeks for new pages to be indexed. With Caffeine, new pages could be found and crawled in seconds.
When was Google Caffeine released?
Google Caffeine was released on June 9th 2010.
How to know if you have been impacted by Google Caffeine?
You weren’t. The update made no changes to any ranking signals and had no impact on the actual SERPs aside from allowing for fresher results.
However, due to the influx of “low quality” pages, Google was now finding and indexing at a faster rate, Caffeine led to Google deciding they needed better quality control in their system, which led to the creation of the first Panda algorithm.
Core Updates
We have covered the role of Google Core Updates a fair amount so far. Around 3-4 times a year Google will launch a significant update to their core ranking system. These systems include all of the algorithms noted above as well as many more that make up the core ranking system.
These are usually some of the most talked-about updates and have historically had some of the biggest impacts on search.
Google Core Updates and Phantom Updates
Recently Google has started to announce when Core Updates take place, and in some cases, they have pre-announced when they may happen such as with the June and July 2021 core updates.
In the past SEOs who follow and track changes to the SERPs used to note dates of significant algorithmic turbulence. We would call these “Phantom Updates”. Recently Google’s Gary Illyes confirm that these were unannounced Core Updates.
Does Google test for core updates?
Yes, Google does extensive testing of the impact that a proposed update will have on the search ecosystem before they roll out a new update. This includes testing using the feedback of the search quality evaluators. In some cases, if they are not satisfied with all of the results (such as with the June and July Core Updates), they have released the updates in parts.
Possible Role of Machine Learning
Google recently released a blog post detailing how they use AI and machine learning in search to better understand queries with technologies such as BERT.
You can read more about these technologies below and also in this article and podcast episode with Dawn Anderson. The more Google learns to understand language, the better they get at understanding what it is the searcher wants to see and presenting them with relevant results. We believe that many of the unexplained but wild shifts in the SERPs in the last few years are a result of Google implementing more and more machine learning capabilities into their algorithms.
However, these are just the systems that Google has disclosed to us that are being used in search and they largely relate to how Google understands queries.
It is, in our opinion, very likely that Google is using AI and machine learning to develop part of the core ranking system itself – to discover new signals to pay attention to, when to pay attention to them, and with what weighting.
How could Google be using machine learning to build algorithms?
In very simplified terms, we believe that Google may be doing something along the lines of the following:
They run a machine learning program that is designed to identify patterns of different signals that correspond to higher quality results than the current ranking system, identifying which weights to give these signals by looking at billions of data points on a per-query basis. These signals and their weightings become the “millions of tiny algorithms” Gary Illyes was talking about.
Only a machine would be able to process this kind of data and spot these kinds of patterns at the scale Google is dealing with.
This process then spits out the proposed changes/additions to the current system which Google engineers then test with the assistance of user data acquired from the search quality evaluators. The evaluators essentially act as the control group.
If the testing done by the engineers shows that the proposed changes (all those millions of tiny algo’s the machine learning found) are producing results that surpass a certain threshold of improved quality they roll out the changes to the live ranking system. This is what core updates are.
That is quite an oversimplification but we hope you get the point. In practical terms, this means that when Google employees or engineers say “it depends” they really mean it. They don’t know what the exact ranking signals and weights are because they don’t know. What they know is that the system is producing better results, and they could pull the exact signals and weightings for a specific query, but that is it.
Fabrice Canal from Bing has told the community explicitly that this is how Bing search works. If Bing is doing this, we are sure Google is.
If you want to learn more about core updates, you may find our article useful: 100 things to know about Google core updates.
We hope you found Part One of this series helpful! In the next edition of this series we will be covering the product review update, page experience algorithms, and much much more!
Callum Scott
 Callum is the Director of Product and Services at MHC. He is responsible for the project management and product development of all MHC’s core service offerings. Callum also maintains a moderate client load as a Senior SEO Analyst with MHC, conducting data driven and qualitative SEO analysis with primary focuses on traffic drop analysis, technical SEO, and site quality assessments.
Callum is the Director of Product and Services at MHC. He is responsible for the project management and product development of all MHC’s core service offerings. Callum also maintains a moderate client load as a Senior SEO Analyst with MHC, conducting data driven and qualitative SEO analysis with primary focuses on traffic drop analysis, technical SEO, and site quality assessments.
Callum has spoken publicly on how to help websites recover from Google’s Core Quality Algorithm Updates at conferences such as DMSS, in Bali, and Invest Ottawa. He contributes frequently for industry publications.

