

I found some interesting things from the latest document in the DOJ vs Google trial. Google has appealed the ruling that says they need to give proprietary information to competitors.
Key takeaways:
- Google has been ordered to give information to competitors so as not to be an illegal monopoly. Google does not want to give their extensive user side data away.
- Google's data on page quality and freshness is proprietary. They don't want to give it away.
- Pages that are indexed are marked up with annotations including signals that identify spam pages.
- If spammers got hold of those spam signals it would make stopping spam difficult.
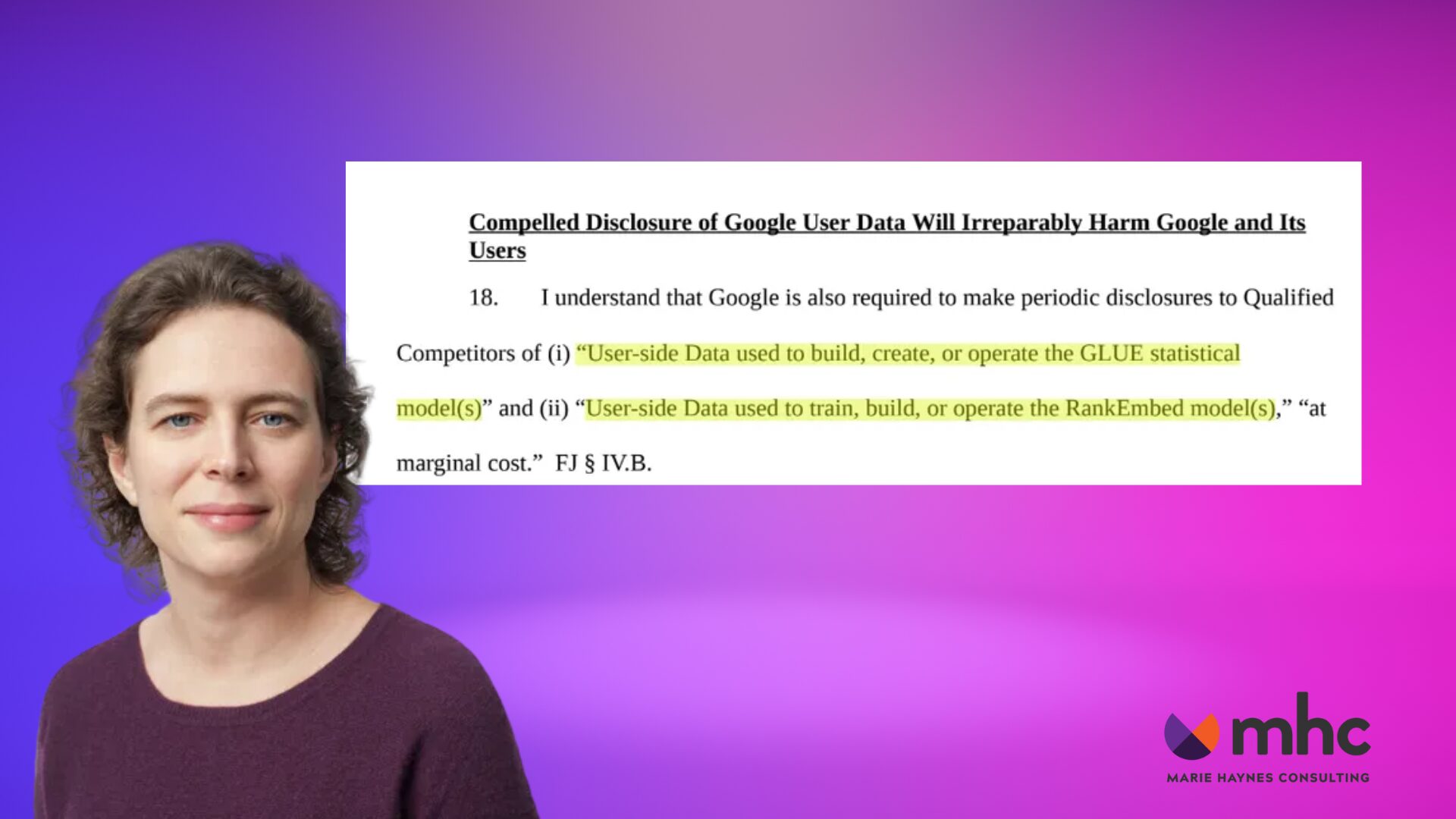
- User data is important to Google's Glue system that stores info on every query searched, what the user saw and how they interacted with the search results.
- User data is important for training RankEmbed BERT - one of the deep learning systems behind Search.
OK, let's get in to the interesting stuff!
Google has proprietary page quality and freshness signals
This really isn't a surprise. I did find it interesting that freshness signals are at the heart of Google's proprietary secrets.

Again, here's more on the importance of Google's proprietary freshness signals:

Pages that are crawled are marked up with "proprietary page understanding annotations"
Every page in Google's index is marked up with annotations to help them understand the page. These include signals to identify spam and duplicate pages. I've written before about how every page in the index has a spam score.

Spam scores could be used to reverse engineer ranking systems
Google doesn't want to share information with their competitors on these scores.

If the spam scores get out, it could lead to more spamming and more difficulty for Google in fighting spam.

Google builds the index using these marked up pages
The pages that Google has added page understanding annotations on are organized based on how frequently Google expects the content will need to be accessed and how fresh the content needs to be.

Only a fraction of pages make it into Google's index
Google argues that giving competitors a list of indexed URLs will enable them to "forgo crawling and analyzing the larger web, and to instead focus their efforts on crawling only the fraction of pages Google has included in its index." Building this index costs Google extensive time and money. They don't want to give that away for free.

The Role of User Data in Google's Ranking Systems
This is the most interesting part. I feel that we do not pay enough attention to Google's use of user data. (Stay tuned to my YouTube channel as I'm soon about to release a very interesting video with my thoughts on how user-side data is so important - likely the MOST important factor in Google's ranking systems.)
User data is used to build GLUE and RankEmbed models
Google Glue is a huge table of user activity. It collects the text of the queries searched, the user's language, location and device type and information on what appeared on the SERP, what the user clicked on or hovered over, how long they stayed on a SERP and more.
RankEmbed BERT is even more interesting. RankEmbed BERT is one of the deep learning systems that underpins Search. In the Pandu Nayak testimony we learned that RankEmbed BERT is used in reranking the results returned by traditional ranking systems. RankEmbed BERT is trained on click and query data from actual users.
The AI systems behind search are continually learning to improve upon presenting searchers with satisfying results. Google looks at what they are clicking on and whether they return to the SERPs or not. Google also runs live experiments that look at what searchers choose to click on and stay on. Those actions help train RankEmbed BERT. It is further fine-tuned by ratings from the quality raters. I will be publishing more on this soon. The takehome point I want to hammer on is that user satisfaction is by far the most important thing we should be optimizing for!
From the Liz Reid document we are analyzing today, we can see that user data is used to train, build and operate RankEmbed models.

Once again we learn that the user data that is used to train these models includes query, location, time of search and how the user interacted with what was displayed to them.

This is talking about the actions that users take from within the Google Search results. What I really want to know is how much of a role Chrome data uses. Does Google look at whether people are engaging with your pages, filling out your forms, making your recipes, and more? I think they do. The judgment summary of this trial hints that Chrome data is used in the ranking systems but not a lot of detail is shared.

Google says that if someone had the Glue and RankEmbed user data they could train an LLM with it
This user data is the key to Google's success.

It's worthwhile reading the whole declaration from Liz Reid.
Also, I am once again offering site quality reviews.
If you liked this, you'll love my newsletter:
Or, join us in the Search Bar for up to the minute news on Search and AI.

Comments are closed.