

Want to learn more about how Google is incorporating artificial intelligence into search? In this article, Dr. Marie Haynes shares her understanding of just that, and a great breakdown of each system Google is using in the following sections:
- Google’s algorithms have changed dramatically over the last few years
- Google is understanding language better than ever before
- RankBrain
- Neural matching
- BERT
- MUM
- Why is Google pushing so hard to have site owners create excellent product pages?
- What can we learn from all of this?
- Does this change how we do SEO in 2022?
Google’s algorithms have evolved immensely over the last few years. In a recent Google blog post, Pandu Nayak wrote about How AI powers great search results. Every SEO should take time to digest this article. I initially tried to summarize it for a tweet and realized that there was so much to discuss that this should be a blog post.
After writing my first draft of this article it became apparent to me that I should practice what I preach in terms of E-A-T and invite a subject matter expert to review my article for accuracy. I reached out to my friend Dawn Anderson. Dawn has thoroughly studied Google’s algorithms in incredible depth and has a postgraduate Diploma as well as a Master of Science in Digital Marketing Strategy. She has been a practicing SEO for many years. I asked Dawn if she could review my article, and she made some very helpful suggestions which I have added. She had so many additional suggestions that we decided to discuss it over Zoom and make a podcast episode out of it.
Thank you for your contributions Dawn! You can read more about Dawn’s credentials and testimonials of her work on her company Bertey’s website. You can also follow her on Twitter. If you want to read more about how Google’s algorithms work, this recent slideshare presentation will blow your mind.
Dawn and I also spoke on this subject in my podcast if you’d like to learn more:
Or, you can watch the video here:
Google’s algorithms have changed dramatically over the last few years
Google’s algorithms have come a long way since SEOs first learned about PageRank. In years past, it was relatively easy to game search algorithms. Today, while some may claim to be able to reverse engineer Google’s algorithms, as Dawn says “it is virtually impossible to reverse engineer today’s algorithms due to their ‘black box’ nature, and the factors of many algorithms working together and the variable weights within each algorithm.”
I believe that our goal as SEOs should not be to reverse engineer Google’s algorithms or to try and game the system, but rather, to understand what it is that Google wants to rank well and recommend to searchers and try to replicate that in our websites. The more we understand about how Google determines quality and the information and value add of content, the more we can provide good advice and recommendations for our clients.
Google is understanding language better than ever before
Pandu Nayak says, “Thanks to advancements in AI and machine learning, our Search systems are understanding human language better than ever before.” The more Google understands language, the better they are at determining what it is that the searcher really wants and connecting them with the right content.
In the early days of Search before Google used advanced AI, they relied heavily on matching keywords in queries with keywords on pages to determine relevancy. Over time Google likely began to introduce some feature engineering into the mix. Dawn shared with me this video in which Google engineer Paul Haahr talks about how Google has improved search over the years. For example, by learning to interpret the order of words, they improved their systems beyond simple keyword matching.
Haahr is speaking about how Google has improved search. He discusses some case studies demonstrating how search has evolved and says he realized that all of them are in one way or another about language. When it comes to search, “language is really important to understanding what we do.”
In the last few years as AI, and in particular unsupervised learning have been added to Google’s capabilities, they are getting better and better at understanding what it is the searcher is trying to accomplish and in turn, connecting them with relevant, helpful and trustworthy content.
As Google improves in this area, the focus has become less and less about matching individual keywords. In better understanding a searcher’s query, Google’s algorithms can now look at things like whether the query is ambiguous, what the intent is behind the query, whether there are contextual details about the user that matter such as their location, and more. As language on pages is better understood, this helps Google connect the most relevant content with the query.
It also becomes harder, if not impossible, to game rankings via traditionally used SEO methods, especially for sites operating in verticals in which they have no real life subject matter expertise or authority. In the past, a good SEO could make content rank even if it wasn’t the best of its kind. Paid links from the right sources could trick Google’s algorithms into considering content as authoritative. When you combine authoritative links with good on-page optimization, success has historically followed.
I’m not saying that link building is dead, but I do believe that Google is getting better at determining which links they should count as authoritative recommendations in their algorithms. Dawn had some interesting thoughts to add here: “One could argue simple classification algorithms can determine easily nowadays whether a link is paid, spam, or poor quality when enough ‘guest blog posts’ have been seen in data for example. The more data, the more the probability accuracy is likely to grow in classifying whether a link is genuine and valuable (e.g. editorially added on a voluntary basis to indicate a worthwhile source)”.
Links do still matter, and Google has not denied this, albeit they do claim content can rank without links. From Dawn, “Hardly surprising, given the Power Law distribution curves of the internet overall and the Zipfian nature of this.” (Note, you can, and probably should read more about Zipfs law and its importance to SEO in Dawn’s presentation. The vast majority of content on the web is in the ‘tail of the web’ where links may not be as important . As per Dawn, “However, in the most competitive head areas of the web links are likely still a strong differentiating factor.”
A 2020 Perficient Digital study showed that links can help drive rankings, but really only links from authoritative sites. I have theorized for some time now that Google is adding more nuance to how they use PageRank in their algorithms as they get better at understanding language.
We know that PageRank and authority are closely related. In Google’s documentation on how they fight disinformation, they tell us that PageRank is one of the signals that correlates with trustworthiness and authoritativeness (two components of E-A-T).

PageRank may be the best known signal Google uses to determine authority, but it is not the only one! For years, it was the most important metric, at least as far as we know. Perhaps it still is, but personally, I think Google has additional ways to determine authoritativeness. I think a lot of how E-A-T is measured on the web relates to Google gathering and understanding entity information.
Dawn shared this video from a 2015 Stanford lecture in which Google’s Xin Luna Dong discusses how algorithms can take entity information on the web and do cross checking and gauge truthfulness. “Validity determination based on probability takes place to estimate confidence on information discovered in web pages.
I’ll share more on entities soon.
My thought is that links are still important to many parts of Google’s algorithms, but when it comes to authority, Google is learning to understand the web beyond the flow of PageRank. Five years ago (which is quite a while in terms of search innovation), Search Engine Land wrote about authority, saying, Google has no single authority metric but rather uses a bucket of signals to determine authority on a page-by-page basis. They stated that while links were still important, AI, and in particular RankBrain, was another important factor.
RankBrain
RankBrain was introduced to Google’s algorithms in 2015. Google’s blog post on AI says it was the first deep learning module used in search. Pandu Nayak called it “groundbreaking”. RankBrain helped Google better understand broad concepts rather than just keywords.
There were many unannounced significant updates in 2015. We do not know which of them introduced RankBrain, but I have some theories.
In May of 2015 we had a big update that Glenn Gabe coined Phantom 2. This was followed by many smaller updates that we called Phantom tremors. We have seen this type of pattern with recent big core and product review updates as well being followed by weeks of SERP turbulence.
Google told Search Engine Land that there was indeed a big change in May of 2015 and we should call it “The Quality Update.” They said that this was not a spam update, but rather, a change to its core ranking algorithm in terms of how it processes quality signals.
Search Engine Land’s recommendation if you were negatively affected by this quality update was to review the questions that Google gave us in 2011 in regards to the Panda Algorithm. These questions are very similar to the ones Google shared with us more recently in their post on what site owners should know about core updates. Some of the original Panda questions are, “Does this article contain insightful analysis or interesting information that is beyond obvious?” and “Does the page provide substantial value when compared to other pages in search results?”
Some argue that an algorithm could not determine the answer to these questions. I think that Google is not completely there yet in promoting pages that answer these quality questions. But, with each core update they get closer. The more they can approximate what it is the searcher is trying to accomplish and which content is relevant and trustworthy, the better they get at surfacing content that is insightful, interesting and provides substantial value.
I do not know for certain whether the “Quality Update” represents Google’s first use of RankBrain in their algorithms. But we know that something fundamentally changed in 2015 with how Google determines quality.
Neural matching
In 2018, Google introduced us to the idea of neural matching. In this article, Ben Gomes wrote about how Google has always tried to provide the user with the most relevant and highest quality information, saying, “This was true when Google started with the Page Rank algorithm—the foundational technology to Search. And it’s just as true today.”
Search has evolved to be much much more than PageRank.
Gomes stated that “we’ve now reached the point where neural networks can help us take a major leap forward from understanding words to understanding concepts.”
Neural networks can take fuzzy concepts and match them with queries. If you search for “why does my TV look strange”, thanks to neural networks, Google’s algorithms can connect the concept of a television looking strange with content that discusses something called the soap opera effect. The page shown in the featured snippet below does not contain the keyword “strange”. In Google’s words, “This can enable us to address queries like: ‘why does my TV look strange?’ to surface the most relevant results for that question, even if the exact words aren’t contained in the page.
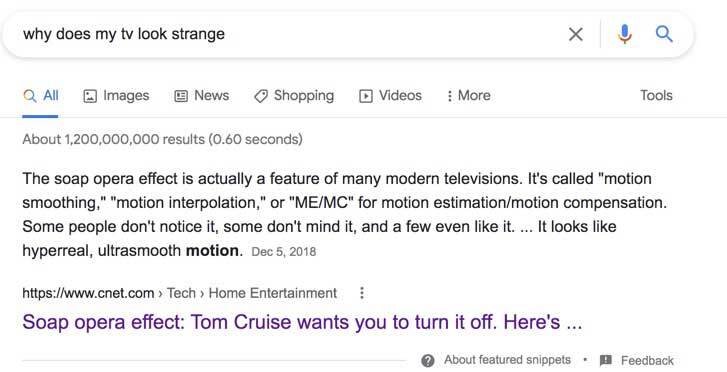
Neural matching does not just apply to understanding concepts in queries, but also on pages as well. This is important. Their blog post says neural matching “looks at an entire query or page rather than just keywords, developing a better understanding of the underlying concepts represented in them.” And also, “When our systems understand the broader concepts represented in a query or page, they can more easily match them with one another.”
Neural networks are fascinating. Google, and in particular Deep Mind own many patents that describe what is possible with neural networks. I was particularly interested in this one which talks about how neural networks can be useful not only for language recognition, but also for named entity extraction and a whole range of other classification, and language processing tasks. As someone new to understanding neural networks, I found this Stanford programming assignment helpful, especially when it comes to understanding how neural networks can be used to extract entities from content. They discuss analyzing language to determine which parts of a sentence are recognized as named entities.
I believe that much of Google’s systems that approximate E-A-T in their algorithms is connected to entities and the associations between them as well. For example, if my name (an entity) is often associated with Search Engine Land or other authoritative entities in terms of SEO, then this could strengthen my authority on SEO related topics. This is why links and mentions are important still, but likely only when they come from authoritative sources. I believe Google is getting much better at knowing which links to count as recommendations.
Here is more information on entity associations from Bill Slawski. In 2014 he wrote that “entity associations are part of the future of SEO”.
Understanding entities and their associations is especially important for sites writing on YMYL topics.
Neural matching represents a big advance in Google understanding what a searcher is looking for and connecting that with content that is the best fit. And neural matching was introduced in 2018 – three years ago!
BERT
Google started using BERT in 2019. Nayak’s blog post says that BERT helps Google “understand how combinations of words express different meanings and intents.”
BERT is very good at helping Google understand the intent behind a complex query. The example that Google gives when describing how BERT helped them improve is the query, “can you get medicine for someone pharmacy”. BERT helps the algorithms understand that the searcher is trying to determine whether you can pick up medicine for someone other than yourself at a pharmacy and then connect the searcher with content that answers that question.
When Google first described BERT, it sounded like it was primarily used for understanding queries. I wasn’t sure whether it was also used to understand content. It sounds to me like BERT does help Google determine which content is relevant as well. Here is what Google told us in their recent blog post:
“Our BERT systems excel at two of the most important tasks in delivering relevant results — ranking and retrieving. Based on its complex language understanding, BERT can very quickly rank documents for relevance.”
BERT was first announced by Google in late October of 2019. It is interesting to note that just a few days later we had an unannounced and significant unnamed Google update on November 8, 2019. As we noted in the article, many of the sites seeing declines had been involved in building links in ways that Google would likely see as unnatural. It is possible that BERT allowed Google’s algorithms to better understand whether a link is a true recommendation that should be given weight in their algorithms. I think what is even more likely though, is that BERT significantly improved Google’s ability to connect a user’s query with content that is relevant, and this resulted in them relying less on PageRank as a signal.
These are all theories. What we do know is that BERT made search better.
And according to Dawn, Google’s use of BERT has advanced and become more powerful over the last two years.
“We also need to bear in mind the BERT of 2018/2019 was extremely computationally expensive and was only really used on short phrases at the time of implementation into live search/launch. However, over the past couple of years BERT in production is likely much more efficient. For example, alBERT, and various other lightweight BERTs were devised, by both Google, other major search companies and the machine learning NLP community. Hybrid models were also created which took the best from several different offerings contributed by the community and other search giants. The present day ‘BERT’s’ are likely very different from the BERT of 2018/2019 due to the hockey stick curve of advancement since then.”
Google is advancing so quickly when it comes to understanding language!
MUM
I believe MUM will radically change the search results we are currently used to seeing. MUM cannot only understand language, but also generate it! And, it uses a framework that’s 1000 times more powerful than BERT.
This scares me a little.
MUM can take information from text, images, video, and even different languages and put it all together to answer questions. It sounds like it will answer questions even before we know what we want to ask in some cases!
Google’s first article on MUM describes a searcher looking for information on climbing mount Fuji. It does not mention a single query, but says that on average, a user curious about this type of adventure would search about eight queries. MUM figures all of that out and presents the user with what they need to know.
It sounds to me like Google is saying MUM will soon allow them to not only determine what it is the searcher is looking for, but actually generate a complex answer.
“Since MUM can surface insights based on its deep knowledge of the world, it could highlight that while both mountains are roughly the same elevation, fall is the rainy season on Mt. Fuji so you might need a waterproof jacket. MUM could also surface helpful subtopics for deeper exploration — like the top-rated gear or best training exercises — with pointers to helpful articles, videos and images from across the web.”
MUM’s only use in search at the current moment is to help Google rapidly make sense of the changing information surrounding Covid-19 vaccines. MUM helped Google identify over 800 variations of vaccine names in more than 50 languages in a matter of seconds.
But we know that more is coming.
At Google’s SearchOn event this year, they spoke about how MUM will eventually integrate with Google Lens.
Say you’re browsing the web using Chrome and you see an image of someone in a shirt. You like the pattern on the shirt and want to find socks with that pattern.
“With this new capability, you can tap on the Lens icon when you’re looking at a picture of a shirt, and ask Google to find you the same pattern — but on another article of clothing, like socks. This helps when you’re looking for something that might be difficult to describe accurately with words alone. You could type “white floral Victorian socks,” but you might not find the exact pattern you’re looking for. By combining images and text into a single query, we’re making it easier to search visually and express your questions in more natural ways.”
There’s a reason why Google has been so vocal lately about improving pages that discuss products.
MUM can also extract topics from videos even if they’re not mentioned by name. It sounds like it will also know whether video is what the searcher is looking for.
Here are some of my tweets from Google’s livestream where they announced MUM and its capabilities.
Pandu Nayak shared that when you point your phone at your broken bike, MUM understands the intent plus the part needed.
Soon we'll be able to point our camera at our bike and even if we don't know the name of the mechanism that's broken, say, "How do I fix this?"
Pandu Nayak says, "We'll show you everything you need to get your bike back on the trail."
MUM understands the part plus your intent. pic.twitter.com/ytWbOkMVmA
— Dr. Marie Haynes🐧 (@Marie_Haynes) September 29, 2021
Google will show you everything you need to fix the problem. “It can then point you to information on how to fix it from a variety of blogs, forums and websites.”
Elizabeth Reid added that MUM will allow Google to “discover creators and publishers you didn’t know existed.”
3. The next change to the SERPS is the option to refine or broaden your search.
Elizabeth says, "These new features are only possible thanks to Google's advanced topic understanding."
They'll allow us to "discover creators and publishers you didn't know existed." pic.twitter.com/s5E3GyP0qM
— Dr. Marie Haynes🐧 (@Marie_Haynes) September 29, 2021
We know that Google has been pushing hard to have site owners produce thorough, high quality product pages. In April of 2021 Google released the Product Reviews Update and then updated it months later in December. These updates had a similar strong impact to many sites as core updates tend to have. This isn’t a surprise to us as Google’s documentation on the update gives questions that are similar to their questions they tell site owners to ask regarding core updates.
All of these questions relate in some way to content quality or E-A-T.
Here are a few:
- Do your reviews express expert knowledge about products where appropriate?
- Do your reviews discuss the benefits and drawbacks of a particular product, based on research into it?
- Do your reviews describe key choices in how a product has been designed and their effect on the users beyond what the manufacturer says?
Google is trying to promote pages that provide “insightful analysis and original research, and [are] written by experts or enthusiasts who know the topic well.” They want to rank pages with good content and good EAT. If you’re not sure what that looks like, in their post on core updates they recommend reading the search quality raters’ guidelines: “If you understand how raters learn to assess good content, that might help you improve your own content. In turn, you might perhaps do better in Search.”
You can read the QRG here or purchase our book that many SEOs use as a checklist to evaluate sites like a quality rater would.
Why is Google pushing so hard to have site owners create excellent product pages?
This next part is what I found the most interesting about Google’s SearchOn Event
6. We'll soon be able to use Google Lens to tap on any part of an image on a site and be shown where to buy it online
-powered by a Machine Learning model to recognize products.
You can then tap to buy it "without leaving the website you are on."
‼️ pic.twitter.com/ShCFxYilZc— Dr. Marie Haynes🐧 (@Marie_Haynes) September 29, 2021
You will soon be able to use Google Lens to select any part of any image on a site and Google will direct you on where to buy this product.
8. Re shopping.
In this example, he searched for hoodies. Results page was well known brands, local shops, video reviews, blog posts and more.
You can then click for comparison info on prices, reviews and ratings.
Powered by "Google's shopping graph" of 24 billion products. pic.twitter.com/gjvEdN5mzf
— Dr. Marie Haynes🐧 (@Marie_Haynes) September 29, 2021
I expect that this will be incredibly lucrative for Google. People want to buy online, but many do not want to use Amazon. Personally, I have found that reviews cannot be trusted and so much of what is on Amazon is junk. I recently bought a sink strainer that shipped from Amazon broken and with food stains. When my husband David went to the post office to return it, they showed him a room absolutely packed with Amazon returns.
In the future, instead of searching Amazon, I can likely search Google for “sink strainer” and MUM will help Google show me much more than Amazon can, including a collection of images, videos and so on to help me determine what to buy. Once I find it, I can click on a part of an image or video and Google will direct me to websites that sell this product.
As Google improves in their efforts to understand and approximate real-world E-A-T, we should find that the websites which Google directs us to make our purchases on are the ones that truly do make and sell good products, have excellent customer service, and are recognized as authorities in their industry. Google dominated search because they were able to produce a search experience that was dramatically better than what existed. I predict that they will eventually do the same with online shopping.
It is also interesting to note that this year Google and Shopify announced a partnership.
It would not surprise me if in the next few years we see searchers begin to trust purchases made through Google searches more than Amazon.
Might be time to buy some Google stock.
What can we learn from all of this?
Five years ago, in 2017, Search Engine Land told us, in an interview with Andrey Lipattsev from Google that when it comes to ranking, what is most important is
- Content and Links
- RankBrain
As mentioned previously, RankBrain was the introduction of AI into Google’s algorithms. The use of AI dramatically changed how they evaluate quality. They told us that an update in May of 2015 changed how they assess quality signals. While we don’t know for certain whether this was the introduction of AI to Google’s quality algorithms, I suspect that the updates we called Phantom and the many tremors that followed represented AI being integrated into the algorithm.
The more Google uses AI in their algorithms, the harder they become to reverse engineer as SEOs. At MHC, we used to try and determine what Google changed with each update! But now, given that much of the results are generated by sophisticated AI, this is close to impossible. Our philosophy is to closely follow all of Google’s documentation and advice they have given on improving quality. We believe that Google is indeed advanced enough to use AI to promote pages that do a good job at answering the questions they recommend webmasters consider in their blog posts. The more we can do to have pages that align with Google’s ideals in terms of quality, the better.
Our approach to site auditing and improving site performance has not changed. Ultimately the different elements of site quality remain true and remain as relevant as ever. At MHC when we review websites we advise on traditional SEO but we also spend a lot of time trying to review the site like a quality rater would. Our site reviews consist of 150+ pages of observations and actionable, implementable recommendations based on years of studying what Google has said about quality.
Does this change how we do SEO in 2022 and beyond?
Good technical SEO will always be important. There will always be room to improve and optimize here, especially for large websites. In 2022 however, most sites operating in competitive verticals have a baseline of good technical SEO in place. While you should always be looking for ways to improve your technical SEO, you’re not likely to overtake smart competitors by doing this.
In my opinion, the sites that have an advantage now are ones who understand these areas:
- Improving E-A-T – this includes making changes on your site to demonstrate your authority and expertise, good use of references and citations, improving external reputation, getting links and mentions from authoritative sources and much, much more. (You can reach out to us if you’d like recommendations for good link/mention builders.) We recommend reading the QRG or our book on how we use the QRG in our site audits.
- Improving content quality (especially in the eyes of the questions in Google’s blog posts listed below)
- Improving site and page hierarchy, schema and UX to help Google and searchers better understand your content and find what they are looking for.
I’ve described more on these topics in our recent blog post and video on 100 things site owners should know about core updates.
Update on January 5, 2023: I’m currently working on an article about what Google’s response ChatGPT looks like. I’ve just re-read this article and realized that if you combine the power of MUM with what we’ve seen is possible with AI chat, we are possibly in for some very wild changes.
Recommended reading:
Google’s Blog post on core updates – lists 20 questions to ask yourself to improve quality
Google’s Blog post on product review updates – lists 9 additional questions to yourself for sites selling or recommending products
How to improve E-A-T for YMYL pages – an article by Marie, published February 2022 on Search Engine Land

Comments
“Google is understanding language better than ever before” – I know they are trying, but I really feel like the Google search experience is getting worse. I’m constantly being served results that are not close to the answers I’m looking for. I’m noticing this for long queries and questions.
IMO Google is learning to process language and they’re in early days. I picture them like a 3 year old right now…some things are right, but they make some mistakes still. I expect we’ll find things gradually improve over the next few years.
Google needs to stop “understanding” lexical queries and just search for what we type. If I want Kardashians, “quote of the day” or song lyrics I will bloody well search for them.
If Google thinks I have a typo it can just ask in the persistent and slightly patronizing way that it used to in 2010, but it shouldn’t substitute completely unrelated synonyms and ignore necessary keywords without feedback from the user while delivering reams of irrelevant garbage. That’s not understanding the query at all.