

This is part 3 of my series working to understand more about the attributes in the recently discovered Google API files.
Navboost is an integral part of Google's core ranking systems. It uses user click data to help refine search results into a smaller group. Navboost stores every query searched along with signals such as which page users clicked on, which ones they lingered on and which pages ended their search. Understanding Navboost helps us realize just how important it is to have content that users find helpful and satisfying. It turns out that what really determines which content is relevant and helpful are the actions of searchers.
Part 1: What is this “leaked” Google documentation?
Part 2: What are attributes?
I first heard about Navboost while reading the Pandu Nayak testimony in the DOJ vs Google case. If you have not yet read this testimony, I encourage you to put aside a few hours to dig in!

As we learn about Navboost it becomes clear that what's important to ranking is to produce web pages that people click on from Search and find helpful.
Learning about Navboost from the Pandu Nayak testimony
The Nayak testimony starts with questioning about user data. Did you know that for every search you perform, the actions you take on Google are monitored and anonymously stored?

Since 2005 Google has used a system called Navboost which stores data about every single search that is performed.

Every query is memorized, along with information about how a user engaged with the Google Search results.
What did they click on after searching that query? Did they click on a specific website? A sitelink? A search feature? Did they click on a site and return to the search results to end up being satisfied by another? Did they swipe through a carousel? Hover over a particular SERP feature? Or perhaps did they click on the first result and not return to search?
It’s not hard to imagine that this type of information could be used to help determine which content people are finding helpful.
We’ll learn what Navboost stores and talk about how Google might use this information. However, I strongly suspect that the way Google uses Navboost information has changed in 2024.
Pandu Nayak says Navboost is not the only system that matters for ranking but “one of the important signals that [they] have.” It is one of the systems that helps Google take thousands of potentially relevant results and narrow that list down to a few hundred.

An internal Google email from 2019 shows that the Navboost system was powerful.

Navboost helps Google understand whether the search results presented to searchers provided them with a satisfying search experience.
Let’s look closer at what Navboost takes into account. It looks at much more than just clicks.
The Life of a Click
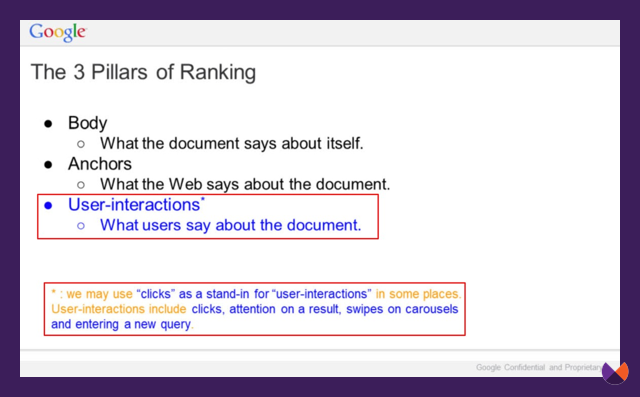
Look at these two slides from a Google presentation during the DOJ vs Google trial called, Life of a Click. I’ve marked in red boxes the parts that help us understand more about which user interactions are used by Google and why. These are referring to user interactions from within the Google Search experience - not on websites themselves. In a moment, we’ll talk about whether Google is using data from Chrome. For now though, these user engagements are referring to actions that users are taking on Google’s search results pages.
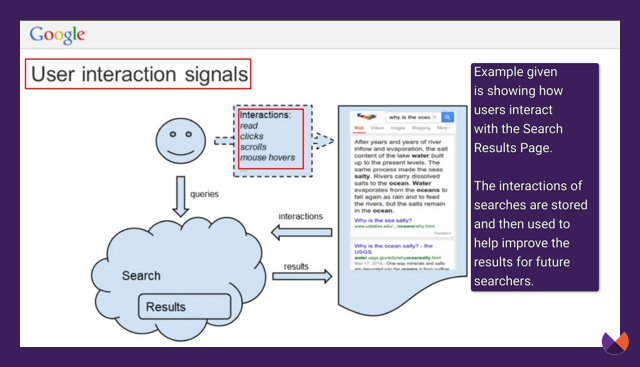
In another presentation called "Q4 Search all Hands" from 2016, Google shares how the actions of previous searchers help Google perform better for future searches.

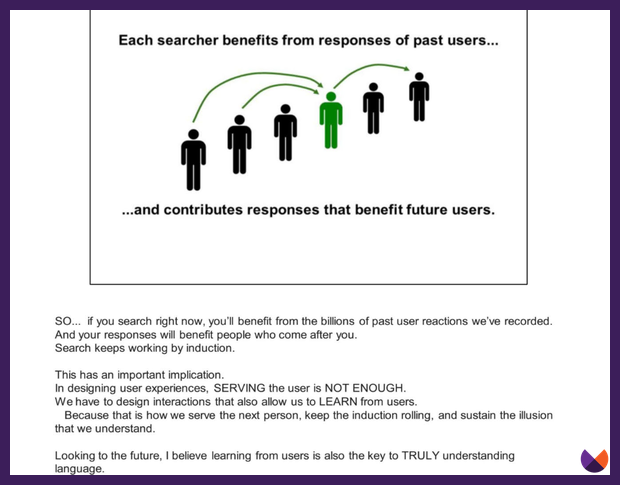
Google learns from the actions of users.
Navboost attributes
The API docs that were discovered this year tell us a lot about the attributes that can be associated with Navboost. What I am most interested in are the attributes that have “Navboost Craps” in the name.
QualityNavboostCrapsCrapsClicksSignals
I could not find anything written about Navboost Craps other than people talking about the attributes listed in this document.

These attributes store information about clicks and impressions. There are a number of things that can be stored and used by a module called QualityNavboostCrapsCrapsData as we will see in the next section.
Here’s the documentation for this module which is used to store data related to Navboost if you want to dig in for yourself.
Navboost stores queries, along with information about the actions of the searcher
We learned above that every query searched on Google is stored by Navboost. There’s an attribute for that:

Several of the variables used by the Navboost module tell us about clicks. The system stores impressions, clicks, goodClicks, badClicks and more. I really would like to know what unicornClicks are.

Navboost puts all of this information together and learns from it. A website that has a high number of lastLongestClicks is more likely to be one that is consistently providing the answer users are looking for. While badClicks aren’t defined in the document, it’s not hard to imagine what they are. I expect they could look at things like whether people consistently return to the search results after clicking on a site and find another site that satisfies their search. A "badClick" is likely a click that didn't satisfy the user. We want to aim to have fewer of those!
For more reading on clicks, I’d encourage you to spend time with Cyrus Shepard’s Moz article which looks at Google patents related to clicks: 3 Vital Click-Based Signals for SEO: First, Long, & Last.
I’d also highly recommend In the Plex by Steven Levy as it talks about long clicks and short clicks. Google has been working for many years now to use this information in algorithms designed to improve its ability to return results that are likely to be helpful.
How do they do this? I’ll share my thoughts shortly. But first, let’s address whether Google is monitoring user interactions on your website itself or whether they are just looking at what people do in the Google Search results.
Does NavBoost use information from Chrome?
There is some debate on whether Google’s systems use information from user interaction in Chrome. It’s certainly possible, as Google’s privacy policy tells us they monitor quite a few things that we do, including how we interact with content, even looking at things like whether we hovered our mouse over an ad or if you interact with a page on which an ad is served.
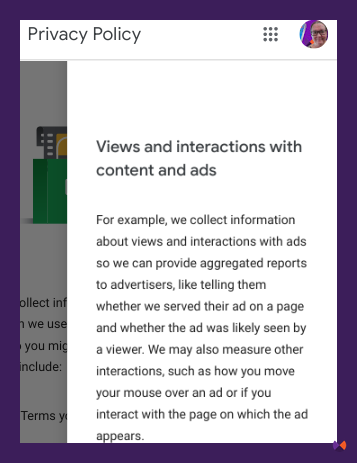
Look at all of these things that Google collects about us.
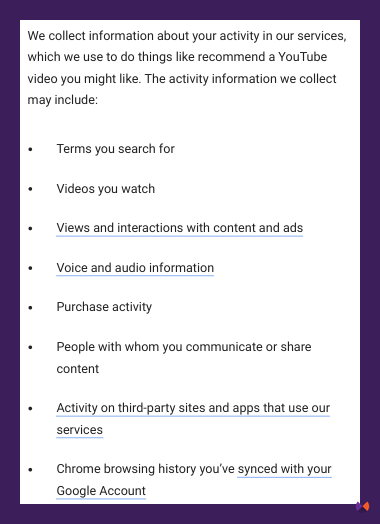
It would make sense to me that Google uses these signals to determine what people find helpful. Google knows, via Chrome, which sites people are making purchases on, which content people are sharing, and more. It’s not hard to imagine that a system could learn which of those pieces of information to use in determining whether pages are likely to be helpful and useful. What would be a better indication of the helpfulness of a recipe page - that it has links pointing to it? Or that people tend to keep the page open, hovering over the recipe section while they make the recipe, sharing it with a friend, and coming back to it repeatedly?
I am only speculating on whether Google uses information about users interacting with websites via Chrome, and perhaps Android as well. I think they do use this information in rankings. What we do know is that Google makes heavy use of user engagement signals by learning from the actions people take on the search results pages themselves.
Although…just to complicate matters more, as the SEO world is now realizing that Google’s systems use click data, I believe it’s possible that Google’s systems are learning how to predict what is likely to be helpful without needing to rely nearly as much on user data, except for one big exception: for fresh queries. We’ll talk more in this series about Instant Glue which uses user signals to help Google understand what’s relevant for fresh, changing searches.
I believe Google’s systems are learning to predict helpfulness without using so much user data
It’s exciting to learn about the Navboost system. It makes sense that results that people click on and engage with, and find to be a satisfying result are more likely to be helpful results.
There is a fault in a system that is built to reward clicks and that is that people can be tricked into clicking via clickbait. The quality raters help mitigate this with their ratings of Search results. If clickbait is causing low quality content to rank better, this should be reflected in the overall quality scores gleaned from quality rater ratings. There’s much more we can say here about how the raters help to fine-tune Google’s ranking systems. My course goes into much more detail.
A Google search system that is so heavily driven by clicks is one that is open to manipulation, especially now that we know the attributes that are associated with Navboost.
Also, how does Google see the quality of new content that has not been presented to users to receive clicks?
I find it incredibly interesting that the “leaked” API files, containing the attributes used in Search were not scrubbed from the internet at the hands of Google’s legal team. How is it possible that this much valuable information telling the workings of the world’s most valuable search engine just falls into our laps?
It's possible that Google initiated significant changes to their search ranking algorithms, starting in March of 2024. This update involved architecture changes and introduced new signals to Google’s ranking systems. The update falls on the heels of Google’s February 2024 announcement of a breakthrough in machine learning with the Gemini 1.5 architecture - a new type of Mixture of Experts model that makes their machine learning systems far more efficient and able to handle vastly more data. Just prior to this announcement, in November of 2023 Google made breakthroughs in developing their Tensor Processing Units, the hardware behind these systems.
I suspect that after many years of studying the actions of searchers, Google's machine learning systems can now do a good job of predicting what searchers are likely to click on, even before any clicks happen. They do this by using a multitude of signals in machine learning systems that determine which ones are best to use for ranking decisions and how much weight to give them. I think it's possible that the attributes that we are studying as part of the API file "leak" are now being used differently by search as machine learning systems continue to learn how to best weigh and consider each one.
We’ll talk about this in the next post of my series…Is it possible Google’s search systems have dramatically changed?
What do we do with this information?
Understanding more about the Navboost system helps us to see just how important it is to focus on user experience. As we create content for the web, we need to be striving to be a result that people will often click on, and then go on to find helpful.
Remember Google’s helpful content documentation? These questions are not a list of things that Google’s algorithms specifically reward but rather, the types of things that people tend to find helpful.
A few of the questions include:
- Does the content provide original information, reporting, research, or analysis?
- Does the content provide insightful analysis or interesting information that is beyond the obvious?
- Is this the sort of page you'd want to bookmark, share with a friend, or recommend?
- Does the content provide substantial value when compared to other pages in search results?
- If someone researched the site producing the content, would they come away with an impression that it is well-trusted or widely-recognized as an authority on its topic?
- Is this content written or reviewed by an expert or enthusiast who demonstrably knows the topic well?
These are the types of things that people like.
It's a real mindset shift to truly create content for people rather than search engines.
There's much more on this in my new book - SEO in the Gemini Era: The Story of How AI Changed Google Search.
Stay tuned for the next post in this series as I'll expound on my theory that the March Core update marked a dramatic change in how Google ranks results.
There's a video to go with this blog post
Here are more of my thoughts on Navboost.
This is part 3 of my series working to understand more about the attributes in the recently discovered Google API files. Here's the first two posts of this series if you haven't read them yet:
Part 1: What is this “leaked” Google documentation?
Part 2: What are attributes?

Leave a Reply